
When Serverless runs on servers: new options for AWS Lambda and AWS Fargate with Managed Instances
04 March 2026 - 13 min. read
Damiano Giorgi
DevOps Engineer


In a world where data drives business innovation, the ability to collect, organize, and analyze it efficiently is crucial. A data lake is a centralized repository that ingests and stores large volumes of data in its original form. Thanks to its scalable architecture, a data lake can accommodate all types of data from any source – structured (relational database tables, csv files), semi-structured (XML files, webpages), and unstructured (images, audio files, tweets) – all without sacrificing fidelity.
AWS offers a comprehensive ecosystem of services that enable you to create and manage data lakes, making them an ideal foundation for a wide range of analytic needs. Additionally, through integrations with third-party services, it’s possible to further enhance a data lake, gaining a holistic and in-depth view of business data.
In this article, we will explore a specific integration between Amazon AppFlow and SAP to prepare data for a data analysis platform.
Let's start defining the main actors in our scenario.
Imagine being able to transfer data between your SaaS applications and AWS quickly, securely, and without implementing complex automation. That’s the magic that Amazon AppFlow offers: a service that simplifies integrations and allows you to automate data flows with just a few clicks, taking care of all the important aspects of data flow integrations. It relieves you of the duties of managing complex infrastructure and writing code to integrate different data sources.
A crucial aspect of data flow integration is the privacy of the connection channel used. Fortunately, AWS helps address this concern with its PrivateLink service. Amazon AppFlow natively integrates with AWS PrivateLink, enabling connections to data sources through a private connection without exposing data to the public internet. This ensures enhanced data security, especially when dealing with sensitive information.
Let's analyze our AWS Organization's setup focusing on the main aspects:
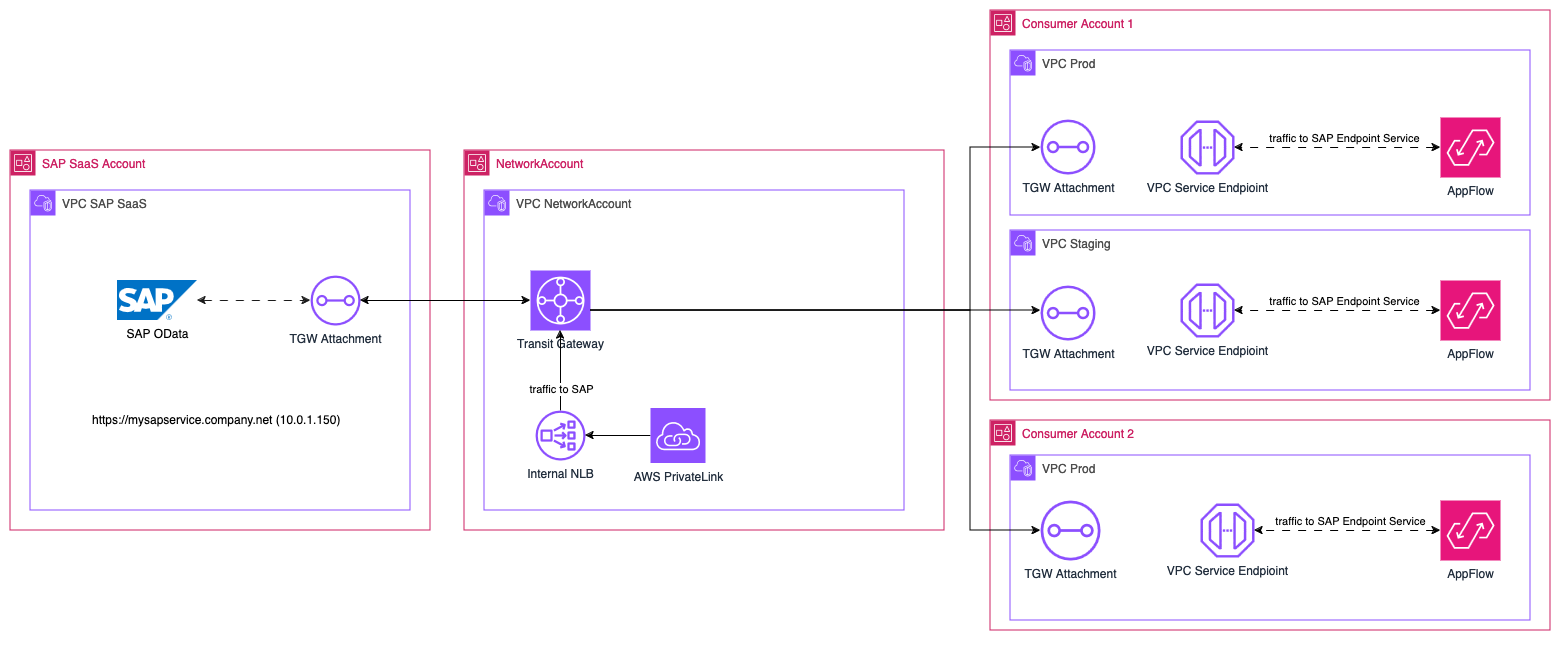
Please note that the SAP-owned account, as well as our accounts are all connected through Transit Gateway VPC Attachments. This scalable network setup ensures that all our current and future AWS accounts will be able to communicate between each other. Another aspect that you should consider is the proper configuration of the routing: following the best practice of least privilege guarantees that accounts have access only to the data and services they are explicitly permitted to use.
Once the SAP services are connected to the main account we need to find an effortless way to make the data available to our consumers. For this purpose, we can use an Endpoint Service powered by AWS PrivateLink
PrivateLink enables us to share a service hosted in AWS with other consumer accounts, it requires a Network Load Balancer (supports also Gateway Load Balancers), which receives requests from consumers and routes them to your service.
In order to configure a private Amazon AppFlow connection, we must first create and verify an Endpoint Service that will be the entry point to the SAP services.
To create the Endpoint Service, you need to consider various things:
Although these steps are more focused on SAP services, you can apply the same principles to any other external services that you want to integrate with your consumer applications in AWS.
Wait a few minutes for provisioning and validation to take effect and you should be ready to go!
Now that we have an Endpoint Service, we can move to the child AWS accounts and create a new Flow that has a SAP OData source.
From the Amazon AppFlow console select SAP OData as Connector type and insert the required parameters for the connection:
Once all fields are filled save and test the connection to SAP.
With the help of Amazon AppFlow and a VPC Endpoint Service, we have achieved a private connection to our datastore in SAP and can now create a new data flow.
For example you can set up a Flow with an S3 Bucket as a destination, you can configure it to run on demand or on a recurring schedule.
You can choose json or csv as output formats, or even better, you can choose parquet format. Using parquet allows you to have highly compressed and optimized data storage, which in turn allows you to optimize storage costs and data querying costs with AWS Athena.
In this article we have covered only the SAP OData Connector, but it is just one of the many integrations that you can set up with Amazon AppFlow. We just scratched the surface of what can be done and the vast possibilities that a data lake gives you. From this starting point you can expand your data lake and ingestion system to accommodate many more integrations with external heterogeneous data sources. This enables you to start analyzing, transforming, and gaining valuable insights from your data from a centralized point of view.
Feel free to explore all the customization options that Amazon AppFlow gives you to find the configuration that fits best to your use case!
Proud2beCloud is a blog by beSharp, an Italian APN Premier Consulting Partner expert in designing, implementing, and managing complex Cloud infrastructures and advanced services on AWS. Before being writers, we are Cloud Experts working daily with AWS services since 2007. We are hungry readers, innovative builders, and gem-seekers. On Proud2beCloud, we regularly share our best AWS pro tips, configuration insights, in-depth news, tips&tricks, how-tos, and many other resources. Take part in the discussion!


