
Quando il Serverless “gira” sui server: nuove opzioni per AWS Lambda e AWS Fargate co...
04 Marzo 2026 - 14 min. read
Damiano Giorgi
DevOps Engineer


In un mondo in cui i dati guidano l'innovazione aziendale, la capacità di raccoglierli, organizzarli e analizzarli in modo efficiente è cruciale. Un data lake è un repository centralizzato che acquisisce e memorizza grandi quantità di dati nella loro forma originale. Grazie alla sua architettura scalabile, un data lake può ospitare tutti i tipi di dati da qualsiasi fonte: strutturati (tabelle di database relazionali, file CSV), semi-strutturati (file XML, pagine web) e non strutturati (immagini, file audio, tweet) - il tutto senza compromettere la fedeltà.
AWS offre un ecosistema completo di servizi che ti consentono di creare e gestire i data lake, rendendoli una base ideale per una vasta gamma di esigenze analitiche. Inoltre, attraverso le integrazioni con servizi di terze parti, è possibile migliorare ulteriormente un data lake, ottenendo una visione complessiva e approfondita dei dati aziendali.
In questo articolo, esploreremo un'integrazione specifica tra Amazon AppFlow e SAP per preparare i dati per una piattaforma di analisi dei dati.
Immagina di poter trasferire i dati tra applicazioni SaaS e il tuo ambiente in AWS rapidamente, in modo sicuro e senza complessità.
Questa è la magia che offre Amazon AppFlow, un servizio che semplifica le integrazioni e ti permette di automatizzare i flussi di dati con pochi click, occupandosi di tutti gli aspetti importanti delle integrazioni dei flussi di dati. Ti solleva dal compito di gestire infrastrutture complesse e di scrivere codice per integrare diverse fonti di dati. Un aspetto cruciale dell'integrazione dei flussi di dati è la privacy del canale di connessione utilizzato. Fortunatamente, AWS aiuta a risolvere questa problematica con il suo servizio PrivateLink. Amazon AppFlow si integra nativamente con AWS PrivateLink, permettendoti di instaurare connessioni a fonti di dati in maniera privata, senza esporre i dati a internet pubblico. Questo garantisce una miglior sicurezza dei dati, soprattutto quando si tratta di informazioni sensibili.
Analizziamo i principali attori nel nostro scenario, come interagiscono tra di loro e come sono organizzati i nostri account AWS:
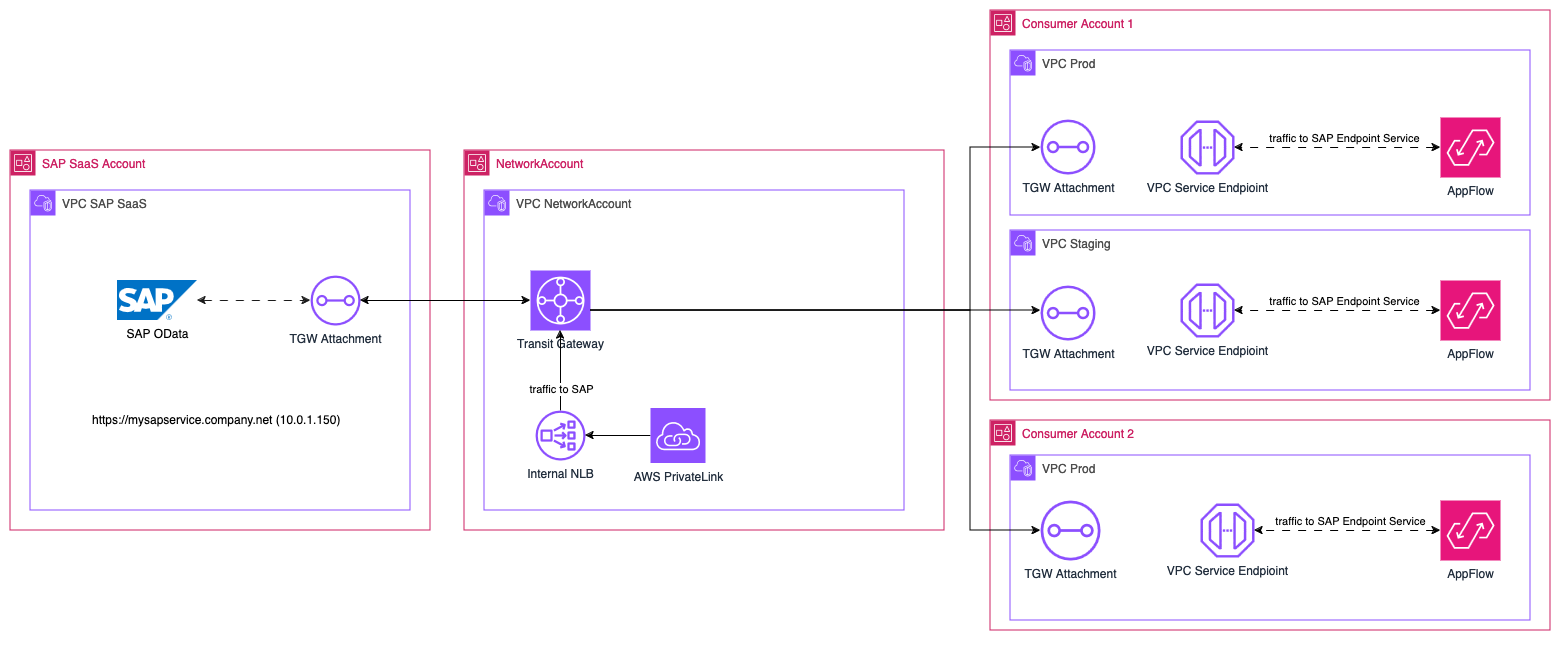
Notate che l'account di proprietà di SAP, così come i nostri account, sono tutti collegati tramite Transit Gateway VPC Attachments. Questa configurazione di rete scalabile garantisce che tutti i nostri account AWS attuali e futuri possano comunicare tra di loro. Un altro aspetto da considerare è la corretta configurazione del routing: seguire la best practice del "least privilege" garantisce che gli account abbiano accesso solo ai dati e ai servizi che sono esplicitamente autorizzati a utilizzare.
Una volta che i servizi SAP sono stati collegati al nostro account principale, dobbiamo trovare un modo semplice per rendere i dati disponibili ai nostri consumatori. A tal proposito possiamo utilizzare un Endpoint Service supportato da AWS PrivateLink.
PrivateLink ci consente di condividere un servizio ospitato in AWS con altri account di consumatori. Richiede un Network Load Balancer (supporta anche i Gateway Load Balancer), che riceve le richieste dai consumatori e le inoltra al tuo servizio.
Per configurare una connessione privata su Amazon AppFlow, dobbiamo prima creare e verificare un Endpoint Service che sarà il punto di ingresso ai servizi SAP.
Per creare l'Endpoint Service, è necessario considerare vari aspetti:
Anche se questi passaggi sono più incentrati sui servizi SAP, è possibile applicare gli stessi principi a qualsiasi altro servizio esterno che si desidera integrare con le applicazioni consumer in AWS.
Aspetta alcuni minuti affinché il provisioning e la verifica del dominio abbiano effetto e dovresti essere pronto per andare avanti!
Ora che abbiamo un Endpoint Service, possiamo passare agli account figli di AWS e creare un nuovo Flow usando SAP OData come sorgente dei dati.
Dalla console di Amazon AppFlow, seleziona SAP OData come tipo di connettore e inserisci i parametri richiesti per la connessione:
Una volta che tutti i campi sono compilati, salva e testa la connessione a SAP.
Con l'aiuto di Amazon AppFlow e di un Endpoint Service VPC, abbiamo ottenuto una connessione privata al nostro datastore in SAP e possiamo ora creare un nuovo flusso di dati.
Ad esempio, puoi configurare un Flow usando un bucket S3 come destinazione, e impostarlo per l'esecuzione on-demand oppure in modo ricorrente.
Puoi scegliere tra json o csv come formati di output, o meglio ancora, puoi scegliere il formato parquet. Utilizzare il formato parquet consente di avere una memorizzazione dei dati altamente compressa e ottimizzata, il che a sua volta permette di ottimizzare i costi di storage e di interrogazione dei dati con AWS Athena.
In questo articolo abbiamo trattato solo il connettore SAP OData, ma è solo una delle tante integrazioni che puoi configurare con AppFlow. Abbiamo appena scalfito la superficie di ciò che può essere fatto e delle vaste possibilità che offre un data lake. Da questo punto di partenza puoi espandere il tuo data lake e il sistema di ingestione per accogliere molte altre integrazioni con fonti di dati eterogenee esterne. Questo ti permette di iniziare ad analizzare, trasformare e ottenere preziosi insight dai tuoi dati da un punto di vista centralizzato.
Sentiti libero di esplorare tutte le opzioni di personalizzazione che Amazon AppFlow offre per trovare la configurazione che meglio si adatta al tuo caso d'uso!
Proud2beCloud è il blog di beSharp, APN Premier Consulting Partner italiano esperto nella progettazione, implementazione e gestione di infrastrutture Cloud complesse e servizi AWS avanzati. Prima di essere scrittori, siamo Solutions Architect che, dal 2007, lavorano quotidianamente con i servizi AWS. Siamo innovatori alla costante ricerca della soluzione più all'avanguardia per noi e per i nostri clienti. Su Proud2beCloud condividiamo regolarmente i nostri migliori spunti con chi come noi, per lavoro o per passione, lavora con il Cloud di AWS. Partecipa alla discussione!


