
Telemetria Enterprise su AWS: Gestire backfill di dati massivi con ECS e Databricks senza far esp...
17 Giugno 2026 - 2 min. read
Keidi Xhafa


Nel panorama tecnologico odierno, in cui la customer experience viene prima di tutto, l'Intelligenza Artificiale è sempre più protagonista.
Tra le sue infinite applicazioni, la creazione di Agent "intelligenti", capaci di interagire con sistemi API-based o direttamente con gli utenti suscita grande interesse sia nel B2B, che nel B2C.
In questo articolo-tutorial vediamo come sviluppare un Agent AI con Claude 3 utilizzando AWS Bedrock. Lo esporremo tramite Amazon API Gateway e AWS Lambda e lo integreremo con con una knowledge base Pinecone per sfruttare l'ottimizzazione dell'output attraverso Retrieval-Augmented Generation (RAG).
Inoltre, vedremo come il sistema può utilizzare AWS Lambda e gli agenti Amazon Bedrock per recuperare informazioni degli utenti direttamente da un database relazionale e visualizzarle in una chat.
Per il tutorial ci serviremo di un esempio pratico: un Agent di assistenza clienti fittizio, capace di gestire richieste su servizi elettrici a Roma. Al termine dell'articolo, avremo ottenuto un Agent AI funzionante, in grado di aiutare i clienti con i servizi, recuperare informazioni sulle fatture e persino inviare email con allegati.
Ti servirà solo una conoscenza di base dei servizi AWS e un po' di esperienza di programmazione.
Cominciamo!
Prima di entrare nel vivo dell'implementazione, discutiamo brevemente le tecnologie chiave che utilizzeremo:
Claude 3, sviluppato da Anthropic, è uno dei modelli di linguaggio avanzati disponibili tramite Amazon Bedrock. Eccelle nella comprensione e generazione del linguaggio naturale, rendendolo ideale per la creazione di Agent AI conversazionali.
Le Knowledge Base di Amazon Bedrock ti permettono di collegare gli Agent AI a repository di dati esistenti, consentendo loro di accedere e utilizzare informazioni rilevanti per migliorare le risposte.
Ecco alcuni punti chiave sulle Knowledge Base e sugli Agent in Amazon Bedrock:
2. Amazon API Gateway e AWS Lambda: Amazon API Gateway è un servizio completamente gestito che semplifica per gli sviluppatori creazione, pubblicazione, gestione, monitoraggio e sicurezza delle API su qualsiasi scala. AWS Lambda è il servizio di calcolo Serverless di AWS che consente di eseguire codice senza dover configurare o gestire server. Insieme, offrono un modo scalabile e conveniente per esporre il nostro Agent AI al mondo.
3. Pinecone: Pinecone è un database vettoriale che consente l'archiviazione e il recupero efficienti di vettori ad alta dimensione, ideale per applicazioni di ricerca semantica.
Progettato specificamente per la gestione, archiviazione e ricerca di vector embeddings, Pinecone offre una soluzione potente per sviluppatori e data scientist che lavorano su progetti di Intelligenza Artificiale.
Pinecone eccelle nella gestione degli embeddings, rappresentazioni numeriche di dati comunemente usate nei modelli di Machine Learning. Questi embeddings possono rappresentare una vasta gamma di informazioni, dai testi e immagini fino ai suoni e ai modelli di comportamento degli utenti. La capacità del servizio di archiviare e interrogare miliardi di questi vettori in modo efficiente lo distingue nel campo della gestione dei dati per le applicazioni AI.
Una delle caratteristiche più rilevanti di Pinecone è la sua scalabilità. Il servizio può gestire miliardi di vettori e processare migliaia di query al secondo senza problemi, rendendolo la scelta ideale per applicazioni su larga scala che richiedono alte prestazioni. Questa scalabilità è accompagnata da una bassa latenza, con tempi di query tipicamente misurati in millisecondi, il che è utile per applicazioni in tempo reale che necessitano di risposte immediate.
Il cuore della funzionalità di Pinecone risiede nelle sue capacità avanzate di ricerca per similarità.
Sfruttando tecniche sofisticate di indicizzazione, tra cui la ricerca approssimativa del "vicino più prossimo" (ANN), Pinecone consente di trovare rapidamente i vettori più simili a un vettore di query, un aspetto cruciale per applicazioni come i sistemi di raccomandazione, la ricerca semantica e il rilevamento di somiglianze in immagini o audio, oltre che, ovviamente, per preparare RAG (Retrieval-Augmented Generation) per i modelli linguistici di grandi dimensioni (LLM). Come soluzione cloud-native, Pinecone offre i vantaggi di un servizio Serverless completamente gestito, riducendo significativamente l'onere operativo per gli utenti e permettendo loro di concentrarsi sullo sviluppo delle applicazioni invece che sulla gestione dell'infrastruttura. Il servizio fornisce una API semplice che si integra facilmente con vari linguaggi di programmazione e framework, rendendolo accessibile a un'ampia gamma di sviluppatori.
La versatilità di Pinecone è ulteriormente migliorata dal supporto per il filtro dei metadati: gli utenti possono allegare informazioni aggiuntive ai loro vettori e utilizzare questi metadati per affinare i risultati di ricerca, cosa fondamentale in scenari dove le informazioni contestuali giocano un ruolo cruciale nel determinare la rilevanza. Il servizio offre anche solide capacità di gestione dei dati, inclusa l'operazione upsert, che consente di aggiornare e inserire facilmente dati vettoriali.
La combinazione di velocità, scalabilità e capacità di ricerca avanzata lo rende uno strumento inestimabile per le organizzazioni che desiderano sfruttare al massimo il loro patrimonio di dati vettoriali.
Nel nostro caso, lo utilizzeremo per archiviare e interrogare informazioni tokenizzate sui servizi elettrici prese da un sito istituzionale.
4. Aurora Serverless PostgreSQL v2: Aurora Serverless è una configurazione on-demand e auto-scalabile per Amazon Aurora. In questo caso, lo utilizzeremo con compatibilità PostgreSQL per archiviare e recuperare dati dei clienti in modo efficiente, sfruttando le Aurora Data API per interagire con il database. L'Aurora Data API è una API HTTPS sicura che consente di eseguire query SQL su un database Amazon Aurora senza la necessità di driver di database o di gestione delle connessioni.
Ecco alcuni motivi per considerare l'uso dell'Aurora Data API:

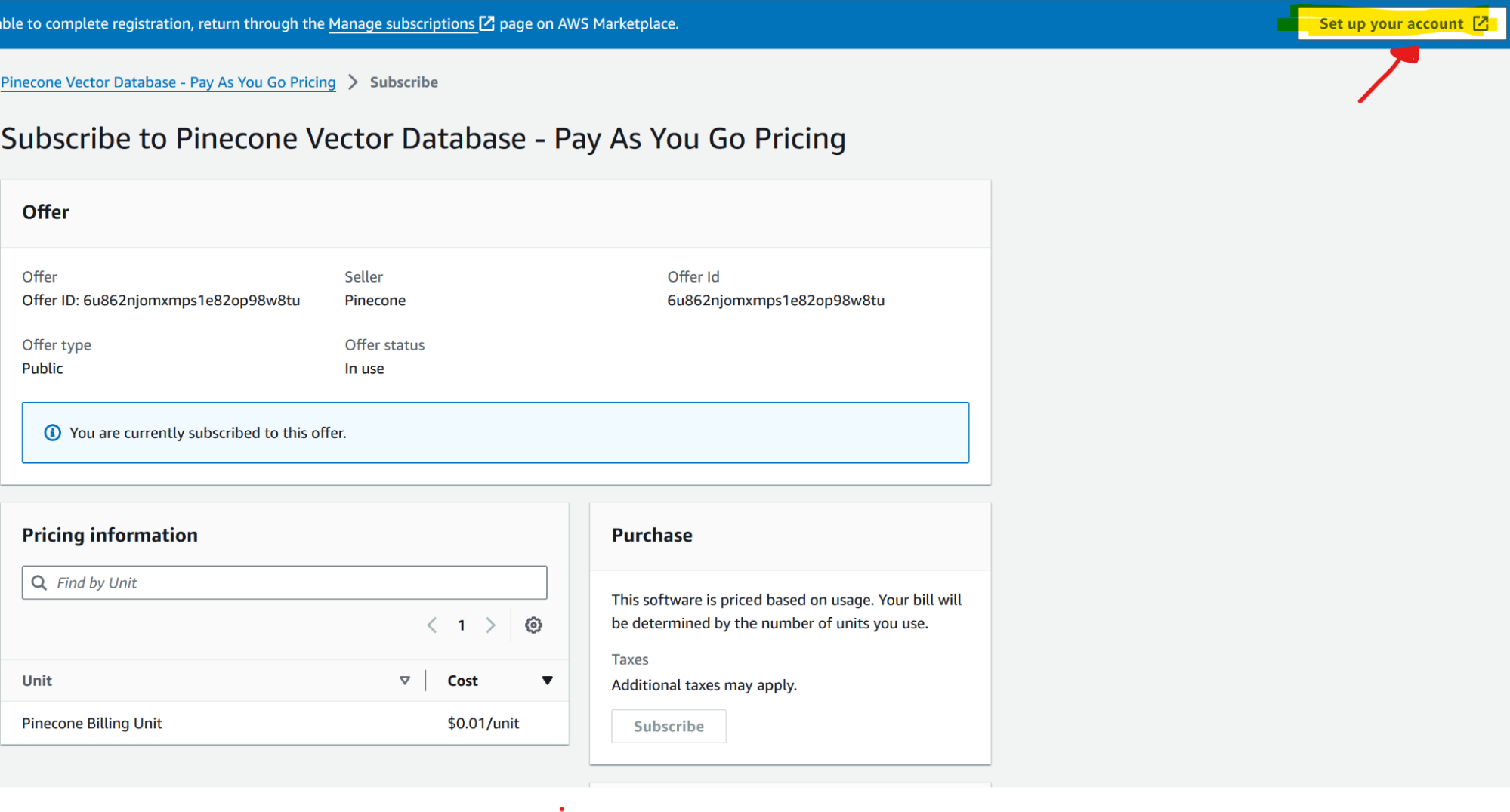
2. Configurazione di Pinecone: Crea un account Pinecone e imposta un nuovo indice per archiviare le informazioni sul servizio. Per iscriversi a Pinecone dal AWS Marketplace, segui questi passaggi:
Dopo l'iscrizione, puoi accedere e utilizzare Pinecone all'interno del tuo account AWS: vai su Marketplace > Gestisci iscrizioni > Configura Prodotto (voce Pinecone) > Configura Account.
3. Configurazione di Aurora Serverless PostgreSQL v2:
Crea un cluster Aurora Serverless PostgreSQL nel tuo account AWS. Configura le tabelle necessarie per i dati. (Consulta la guida specifica per questo passaggio)
4. Creazione dell'Agente Claude 3 con AWS Bedrock:
Accesso ad Amazon Bedrock
Naviga nella console di Amazon Bedrock e richiedi l'accesso al modello Claude 3:
5. Configurazione del Knowledge Base in Bedrock:
Abbiamo scaricato il testo dalle pagine web dei clienti, ma puoi caricare tutti i documenti che ritieni utili nel KB. I formati supportati sono testo e PDF. Se utilizzi Opensearch Serverless (il database vettoriale nativo di AWS), puoi anche collegare fonti di dati aziendali interne come Sharepoint, Confluence, Salesforce e crawler web generici.
6. Definizione del Comportamento dell'Agent:
Utilizzando il seguente metaprompt, o qualcosa di simile, definisci il comportamento dell'agent. Questo include specificare il suo ruolo come agent del servizio clienti, delineare i compiti principali e impostare le linee guida per l'interazione.
Esempio di metaprompt:
You are a customer service agent. Your main task is to help the customer by answering their questions about provided services. You have to:
1. Provide information about these services: Interventi sul punto di fornitura, Illuminazione cimiteriale, Allaccio alla rete elettrica. You can find the information in your knowledge base.
2. List all the customer's invoice. The customer has to provide numero utenza and tipo utenza (bollette energia oppure bolletta illuminazione cimiteriale) in the prompt.
3. Get all the information of a single invoice. The customer has to provide numero bolletta in the prompt.
4. Send mail with a single invoice attached. The customer has to provide numero bolletta and email address in the prompt.
You need to have all the required parameters to invoke the action group. Don't complete the missing parameters. Ask the customer to provide the missing one.
If the provided email is formally wrong you have to ask the customer to insert a valid email
If you have found invoices that match the user's criteria print them in a user friendly format. Always reply in italian.
If you can't find any invoice on the criteria provided by the user, use a polite tone to let him know that you were unable to find any invoices that met the user's search criteria. Ask them to try again and give them guidance on what criteria their missing to get results that best meet their criteria. You also need to be flexible. If it doesn't match their exact criteria, you can still state other invoices you have in the desired period.
When you provide answers don't link any vector db source reference.
Don't answer to other topic questions.7. Implementazione della Logica dell'Agent:
Crea una nuova funzione Lambda che fungerà da backend per il nostro agent. Questa funzione permetterà a Claude di eseguire operazioni definite nel file OpenAPI che dovrai caricare nell'agent, nel gruppo di azioni.
Ecco un semplice esempio di codice per la funzione Lambda:
import json
import boto3
# Replace these with your actual ARNs
db_clust_arn = "your_database_cluster_arn"
db_secret_arn = "your_database_secret_arn"
rds_data = boto3.client("rds-data")
s3_client = boto3.client("s3")
def lambda_handler(event, context):
print(event)
agent = event["agent"]
action_group = event["actionGroup"]
# Flatten parameters for easier access
flattened_params = {param["name"]: param["value"] for param in event["parameters"]}
print(flattened_params)
parameters = event.get("parameters", [])
print(parameters)
invoice_number = parameters[0].get("value")
receiver_email = parameters[1].get("value")
# Construct SQL query
get_invoice_information_sql = f"""
SELECT *
FROM invoices
WHERE account_number = '{flattened_params['account_number']}'
"""
if flattened_params.get("account_type"):
get_invoice_information_sql += (
f" AND account_type = '{flattened_params['account_type']}'"
)
print(get_invoice_information_sql)
# Execute SQL query
response = rds_data.execute_statement(
resourceArn=db_clust_arn,
secretArn=db_secret_arn,
database="your_database_name",
sql=get_invoice_information_sql,
)
print(response)
records = response.get("records")
print(records)
# Prepare response
response_body = {"TEXT": {"body": f"{records}"}}
action_response = {
"actionGroup": action_group,
"functionResponse": {
"responseState": "REPROMPT",
"responseBody": response_body,
},
}
session_attributes = event["sessionAttributes"]
prompt_session_attributes = event["promptSessionAttributes"]
# Construct final Lambda response
lambda_response = {
"response": action_response,
"messageVersion": event["messageVersion"],
"sessionAttributes": session_attributes,
"promptSessionAttributes": prompt_session_attributes,
}
return lambda_responseOra che abbiamo la funzione Lambda, possiamo proseguire aggiungendo le azioni API e registrando la Knowledge Base (KB) nell'agente che abbiamo creato in precedenza. Torna alla dashboard dell'agente e modifica l'agent aggiungendo la Knowledge Base creando un nuovo gruppo di azioni.
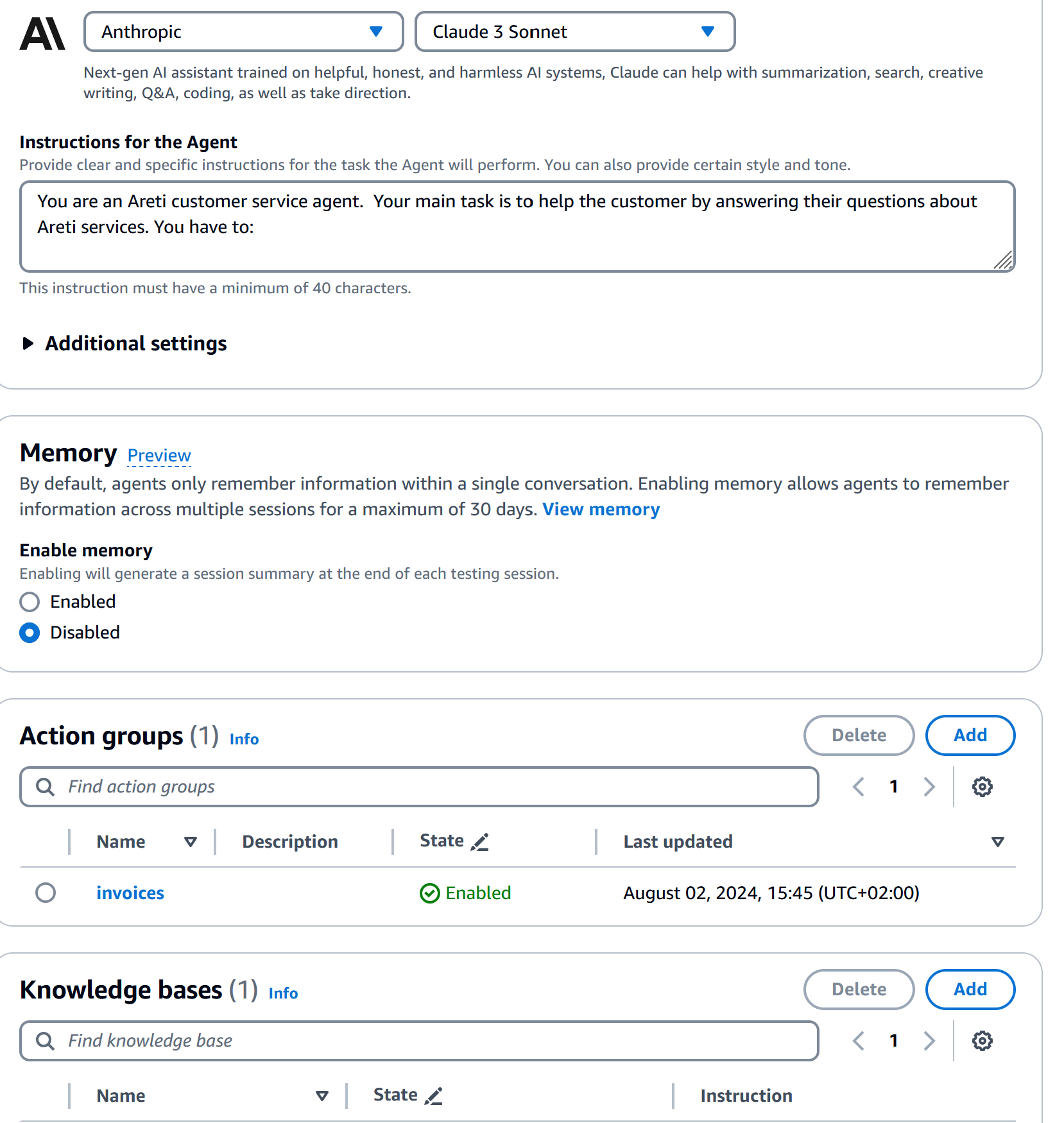
Puoi aggiungere un nuovo gruppo di azioni inserendo le istruzioni e un file OpenAPI Swagger YAML.
Ecco il nostro esempio:
openapi: 3.0.0
info:
title: invoices service
version: 1.0.0
description: APIs for retrieving customer's invoices
paths:
/list-invoices/:
get:
summary: recupera la lista di bollette dati numero utenza e tipo utenza
description: recupera la lista di bollette, quindi numero bolletta, periodo e importo, dati numero utenza e tipo utenza
operationId: listInvoices
parameters:
- name: numero_utenza
in: path
description: Numero di utenza dell'utente che fa la richesta, è necessario che sia fornito dall'utente
required: true
schema:
type: string
- name: tipo_utenza
in: path
description: Tipo di utenza dell'utente che fa la richiesta, valori ammessi "Energia Elettrica" e "Illuminazione Cimiteriale"
required: false
schema:
type: string
enum:
- Energia Elettrica
- Illuminazione Cimiteriale
responses:
"200":
description: recupera la lista di bollette dati numero utenza e tipo utenza
content:
application/json:
schema:
type: array
items:
type: object
properties:
numero_utenza:
type: string
description: Numero di utenza dell'utente che fa la richesta
tipo_utenza:
type: string
description: Tipo di utenza dell'utente che fa la richiesta
link_pdf_bolletta:
type: string
description: S3 URI del pdf della/delle bolletta/e richieste
/get-invoices/:
get:
summary: Recupera tutti i dettagli di una singola bolletta, dato il numero di bolletta
description: Recupera tutti i dettagli di una singola bolletta, dato il numero di bolletta
operationId: getInvoices
parameters:
- name: numero_bolletta
in: path
description: Numero della bolletta, è necessario che sia fornito dall'utente
required: true
schema:
type: string
responses:
"200":
description: Recupera tutti i dettagli di una singola bolletta, dato il numero di bolletta
content:
application/json:
schema:
type: array
items:
type: object
properties:
numero_utenza:
type: string
description: Numero di utenza dell'utente che fa la richesta
tipo_utenza:
type: string
description: Tipo di utenza dell'utente che fa la richiesta
link_pdf_bolletta:
type: string
description: S3 URI del pdf della/delle bolletta/e richieste
/list-readings/:
get:
summary: Recupera tutti le letture per codice contratto
description: Recupera tutte le letture per codice contratto
operationId: listReadings
parameters:
- name: codice_contratto
in: path
description: codice contratto, è necessario che sia fornito dall'utente
required: true
schema:
type: string
responses:
"200":
description: Recupera tutti le letture tramite codice contratto
content:
application/json:
schema:
type: array
items:
type: object
properties:
codice_contratto:
type: string
description: Codice del contratto utenza
/send-mail/:
get:
summary: Inviare una mail con allegata la bolletta richiesta, dato il numero bolletta e l'indirizzo email del cliente
description: Inviare una mail con allegata la bolletta richiesta, dato il numero bolletta e l'indirizzo email del cliente
operationId: sendMail
parameters:
- name: numero_bolletta
in: path
description: Numero della bolletta, è necessario che sia fornito dall'utente
required: true
schema:
type: string
- name: email
in: path
description: Inviare una mail con allegata la bolletta richiesta, dato il numero bolletta e l'indirizzo email del cliente
required: true
schema:
type: string
responses:
"200":
description: Recupera tutti i dettagli di una singola bolletta, dato il numero di bolletta
content:
application/json:
schema:
type: array
items:
type: object
properties:
numero_utenza:
type: string
description: Numero di utenza dell'utente che fa la richesta
tipo_utenza:
type: string
description: Tipo di utenza dell'utente che fa la richiesta
link_pdf_bolletta:
type: string
description: S3 URI del pdf della/delle bolletta/e richieste
Di seguito puoi trovare la nostra configurazione nella sezione dei gruppi di azione:
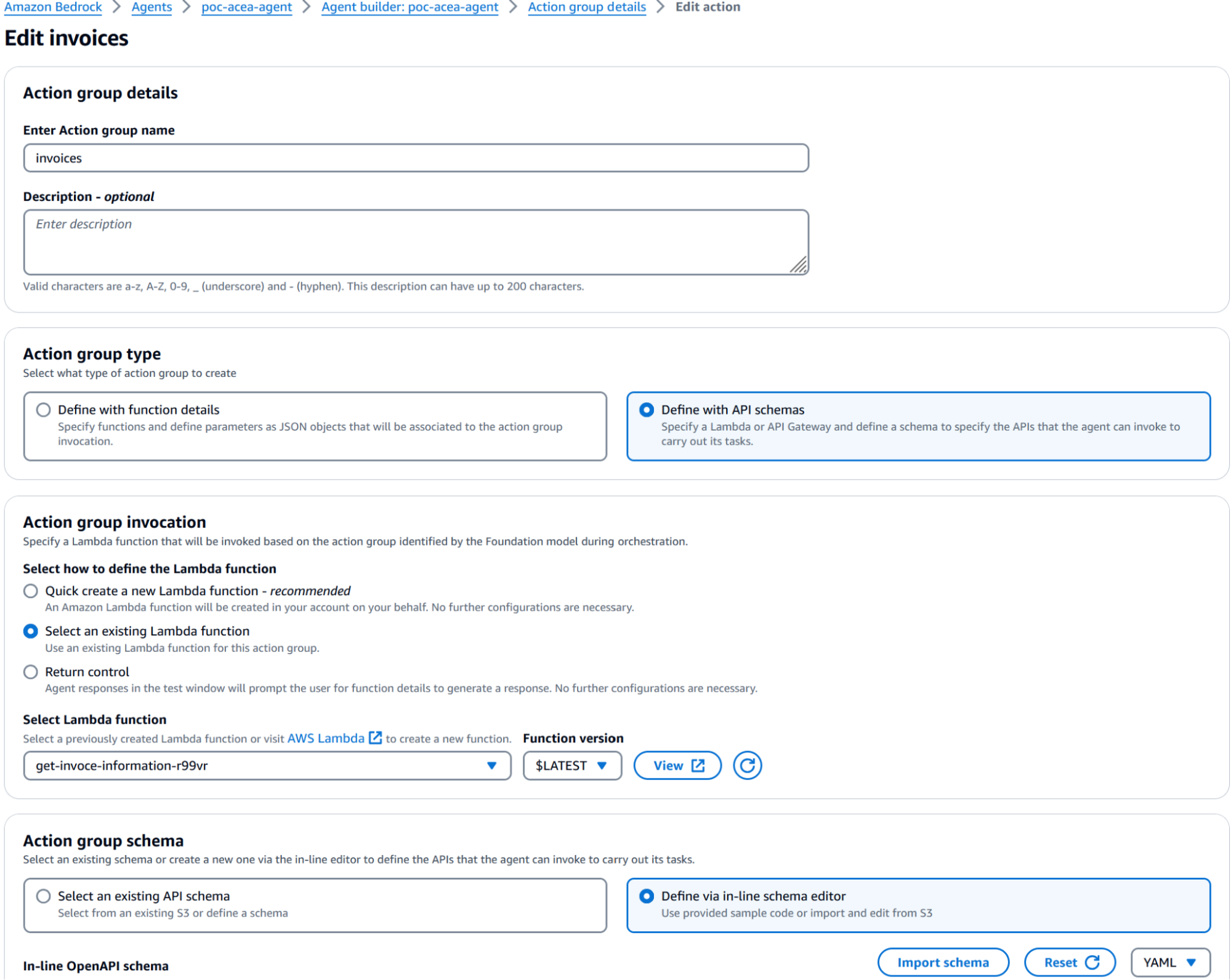
Dopo aver completato questa configurazione, dovresti essere in grado di invocare l'agent tramite l'ambiente di test integrato. Ricorda di salvare e pubblicare l'agent prima di effettuare il test. Se qualcosa dovesse fallire, puoi trovare l'errore nell'ambiente integrato; un errore molto comune è non impostare correttamente la policy delle risorse Lambda
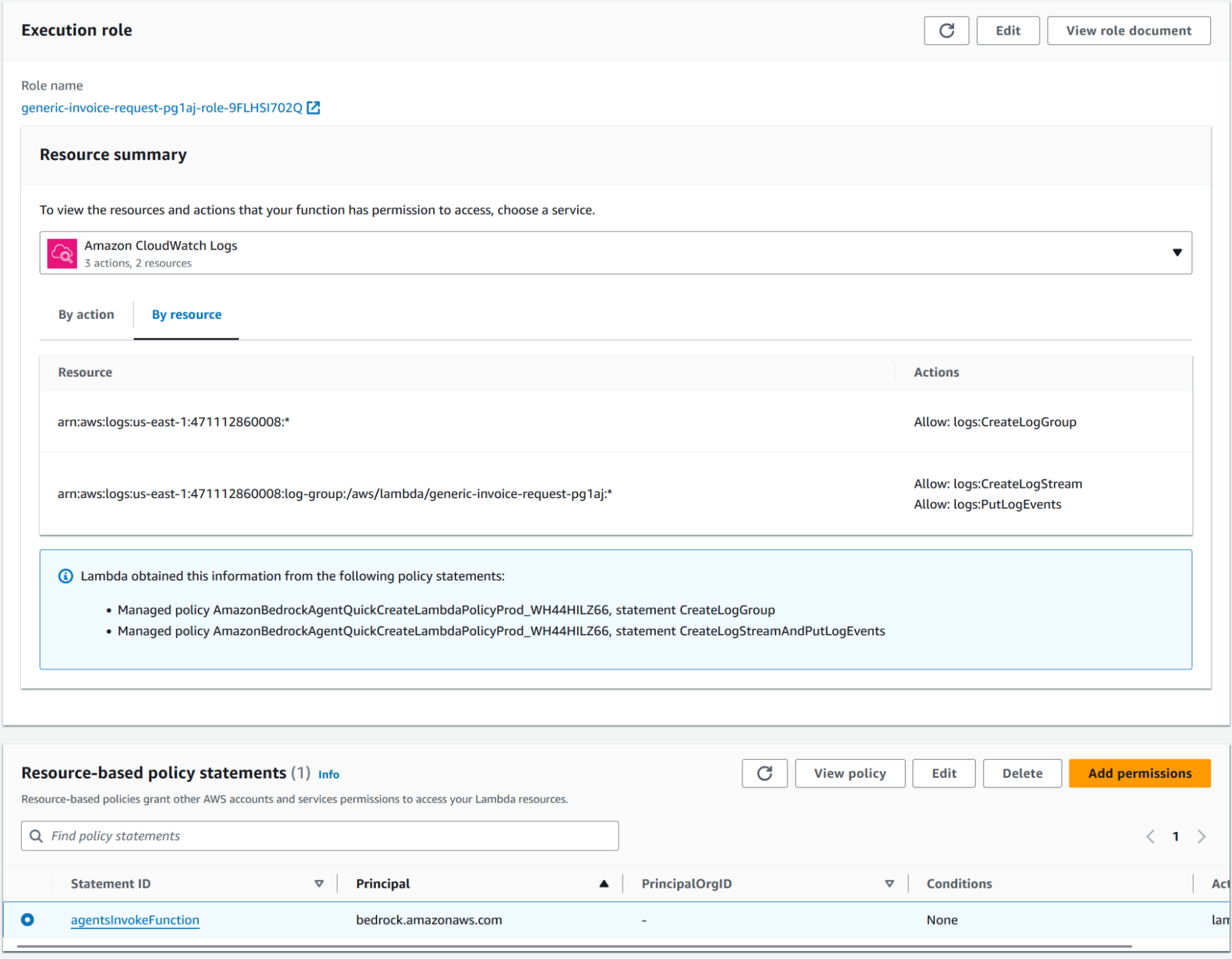
Lo statement dell'agentsInvokeFunction dovrebbe essere simile a questo:
{
"Version": "2012-10-17",
"Id": "default",
"Statement": [
{
"Sid": "agentsInvokeFunction",
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "lambda:invokeFunction",
"Resource": "arn:aws:lambda:us-east-1:471112860008:function:generic-invoice-request-pg1aj"
}
]
}8. Impostazione della Registrazione (Logging):
Per configurare la registrazione in AWS Bedrock:
Dovresti anche abilitare la registrazione per il Knowledge Base.
9. Esposizione dell'Agent tramite Amazon API Gateway
Nella console AWS Lambda, crea una nuova funzione Lambda in Python. La funzione Lambda utilizzerà boto3 per invocare l'agent Bedrock con il prompt dell'utente.
Ecco un semplice esempio:
import boto3
import json
import random
import string
# Replace these with your actual Agent IDs
AGENT_ID = "YOUR_AGENT_ID"
AGENT_ALIAS_ID = "YOUR_AGENT_ALIAS_ID"
bedrock_agent_runtime = boto3.client("bedrock-agent-runtime")
def lambda_handler(event, context):
print(event)
# Parse the incoming event body
body = json.loads(event["body"])
print(body)
session_id = body["sessionId"]
input_text = body["message"]
client_code = body["clientCode"]
# Invoke the Bedrock agent
response = bedrock_agent_runtime.invoke_agent(
enableTrace=True,
agentId=AGENT_ID,
agentAliasId=AGENT_ALIAS_ID,
sessionId=session_id,
inputText=input_text,
)
print(response)
# Process the response chunks
resp_text = ""
for chunk in response["completion"]:
print(chunk)
if "chunk" in chunk:
decoded_chunk = chunk["chunk"]["bytes"].decode()
print(decoded_chunk)
resp_text += decoded_chunk
# Prepare the response
response = {
"statusCode": 200,
"headers": {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": True,
},
"body": resp_text,
}
return response
Nella console di API Gateway, crea una nuova API REST. Configura una risorsa e un metodo POST che attiverà la tua funzione Lambda, quindi configura l'integrazione tra Amazon API Gateway e la tua funzione Lambda. Assicurati che siano in atto i permessi necessari affinché Amazon API Gateway possa invocare Lambda. Distribuisci la tua API su uno stage (ad es., "prod") e annota l'URL di invocazione, che è l'URL che i clienti utilizzeranno per interagire con il tuo agente.
10. Test e Affinamento
Utilizza strumenti come Postman o curl per inviare richieste al tuo endpoint API e verificare che l'agent risponda correttamente. Testa vari scenari, inclusi:
Affina poi il comportamento del tuo agent regolando il metaprompt, ottimizzando i parametri del modello Claude 3 o modificando la logica della tua funzione Lambda.
Sii consapevole dei modelli di pricing dei servizi che stai utilizzando:
In questo tutorial, abbiamo esaminato il processo di creazione di un agente Claude 3 utilizzando Amazon Bedrock e la sua esposizione tramite Amazon API Gateway e AWS Lambda. L'abbiamo integrato con una Knowledge Base Pinecone per le informazioni sui servizi e collegato ad Aurora Serverless per il recupero dei dati dei clienti.
Questa configurazione offre una soluzione potente, scalabile e conveniente per la creazione di agent di customer service basati su AI.
Sfruttare i servizi Serverless di AWS, consente di concentrarsi sul perfezionamento delle capacità del tuo agent senza preoccuparti della gestione dell'infrastruttura.
Man mano che continui a sviluppare e migliorare il tuo agente, ricorda di rivedere regolarmente le sue prestazioni, raccogliere feedback dagli utenti e rimanere aggiornato sugli ultimi sviluppi in ambito AI e tecnologie Cloud.
Speriamo che questo articolo ti sia stato utile per trovare ispirazione per migliorare i tuoi servizi.
Ci vediamo tra 14 giorni su Proud2beCloud per un nuovo articolo!
Proud2beCloud è il blog di beSharp, APN Premier Consulting Partner italiano esperto nella progettazione, implementazione e gestione di infrastrutture Cloud complesse e servizi AWS avanzati. Prima di essere scrittori, siamo Solutions Architect che, dal 2007, lavorano quotidianamente con i servizi AWS. Siamo innovatori alla costante ricerca della soluzione più all'avanguardia per noi e per i nostri clienti. Su Proud2beCloud condividiamo regolarmente i nostri migliori spunti con chi come noi, per lavoro o per passione, lavora con il Cloud di AWS. Partecipa alla discussione!


