
When Serverless runs on servers: new options for AWS Lambda and AWS Fargate with Managed Instances
04 March 2026 - 13 min. read
Damiano Giorgi
DevOps Engineer



It's no longer just a quote, but a mantra:
"Everything fails, all the time" - Werner Vogels
This principle has influenced the methodology behind designing cloud infrastructures. It is necessary to assess different types of failures before designing. However, not all disasters are the same. Let's try to classify them:
To effectively respond to these three types of disasters, different design and planning approaches are required:
In this series of articles, we will focus specifically on Disaster Recovery, from its definition to recovery techniques and how the AWS service ecosystem can help ensure business continuity in any situation.
Disaster Recovery (DR) is a fundamental process to ensure the continuity of business operations in the event of IT disasters. There are different DR techniques, and all aim to restore applications, data, and IT infrastructure as quickly as possible after an adverse event.
In the Cloud context, DR is even more critical because applications and data are hosted remotely on servers and infrastructures that can experience service disruptions due to connectivity issues, hardware failures, cyberattacks, or natural disasters.
Whenever this topic is addressed and to ensure effective DR, it is necessary to start with two key acronyms that are essential for selecting the best DR strategy:

In summary, DR is a fundamental process to ensure the continuity of business operations in the event of IT disasters, and its effectiveness depends on the RTO/RPO objective and the right balance between consistency, availability, and fault tolerance.
There are several approaches to Disaster Recovery, and the choice depends on factors such as budget, data and application criticality, acceptable recovery time (RTO), and acceptable recovery point (RPO). Among the most common methods for DR, we have:
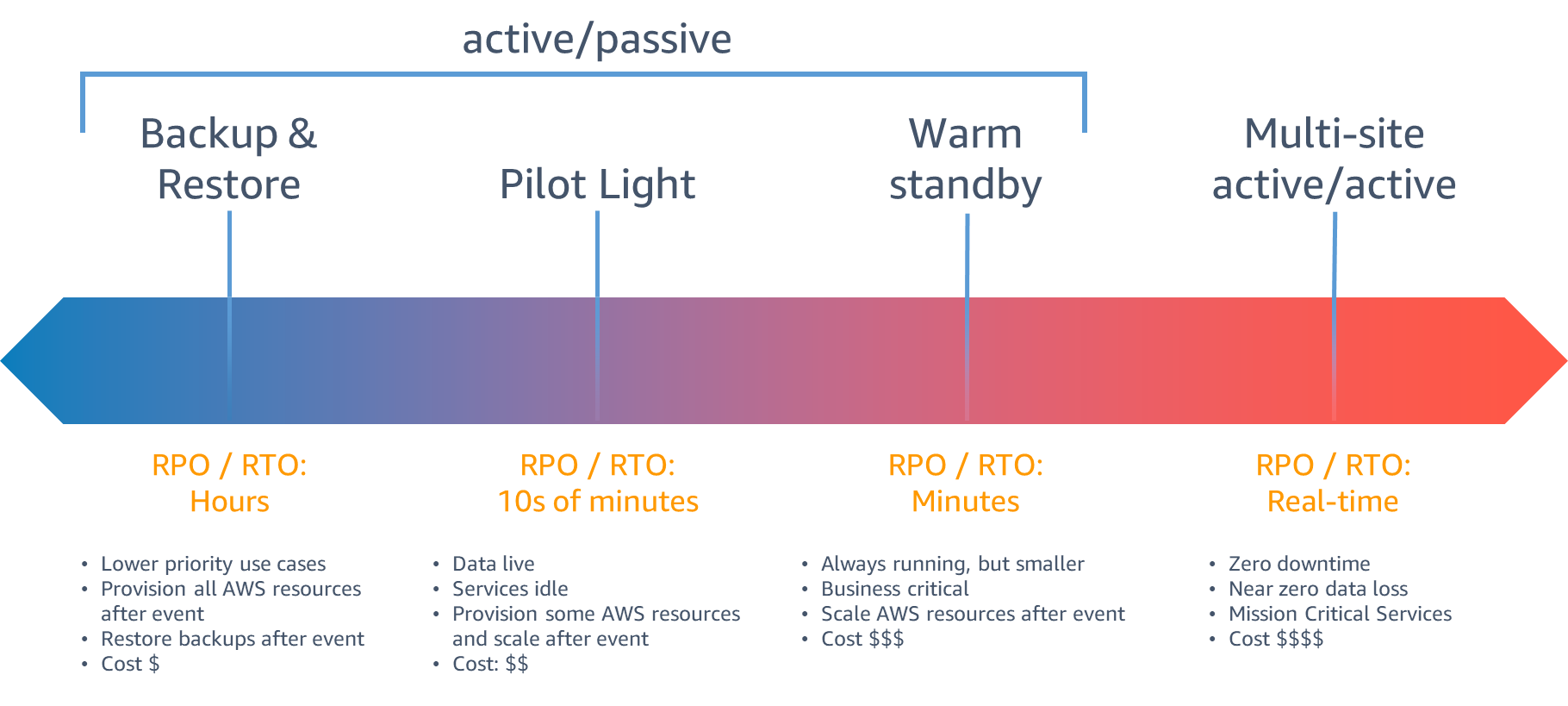
Regarding the application of DR techniques in different-sized realities, it can be said that each organization must choose the most suitable method according to its needs and resources. Larger companies often have higher budgets and can afford to invest in expensive infrastructures like active replicas that are constantly synchronized. On the other hand, small and medium-sized enterprises can opt for more cost-effective and flexible solutions, such as data replication in the cloud.
In summary, the choice of Disaster Recovery method depends on the organization's needs, budget, and the criticality of data and applications. While the process of replicating data for disaster recovery may seem clear and straightforward, there are several technical factors to consider that can affect RPO/RTO (Recovery Point Objective/Recovery Time Objective). Some of the main factors include:
Of course, the blanket is always too short, and we must be aware that disaster recovery must necessarily be a compromise. In support of this, I would like to mention a fundamental theorem for distributed systems: the CAP theorem.
The CAP theorem (Consistency, Availability, Partition tolerance), which normally applies to distributed database systems, can be similarly applied in the context of Disaster Recovery (DR) with some additional considerations. Also known as Brewer's theorem, it states that it is impossible for a distributed computer system to simultaneously provide all three of the following guarantees:
When applying the CAP theorem to DR, a conscious choice is often made to balance consistency, availability, and partition tolerance based on specific business needs and the consequences of disruptions. For example, in a prioritized recovery environment, availability may be given priority, temporarily sacrificing data consistency. Conversely, in an environment highly sensitive to consistency, consistency may be prioritized, temporarily sacrificing availability.
All this is just to understand how disaster recovery is done, and how we transition from production to our secondary site. But there is a crucial point in the matter that is essential and often overlooked by everyone, which is designing how to return to production after the disastrous event has subsided. In short, we always forget to define how to "go back."
In this case, it is important to follow a well-planned process to ensure a safe and smooth transition.
First and foremost, a recovery assessment must be conducted. Before returning to normal production, it is necessary to carefully assess the state of the system and the production environment. Verify that the problem or disruption event has been completely resolved and that the environment is ready for restoration. In this case, having good monitoring systems is crucial to detect any anomalies or issues. The use of monitoring tools and alerts is helpful in identifying and promptly resolving any problems that may occur during the transition back to production. Repetition helps: monitoring is also crucial post-restoration to identify any residual issues or side effects that may arise and to intervene promptly to resolve them.
It is not enough for the production environment to be finally available; testing and validation must be performed. This may include functional testing, load testing, and other appropriate tests to ensure that everything functions correctly as expected. Verify that the data is consistent and intact.
In some cases, it may be necessary to perform a rollback of the changes made during the DR process. This may involve restoring configurations, application changes, or previous versions of data. It is important to plan the rollback in order to minimize the impact on operations and ensure data consistency.
Communication with users and stakeholders involved should not be underestimated in emergency situations. The individuals involved must be made aware of the changes made and the necessary steps to return to normal production.
To inform the involved individuals, it is necessary to document our procedures, recording all the steps, changes made, and actions taken during the DR process. This will help reconstruct the disruption event and analyze it later to improve future DR strategies.
Additionally, we conclude with a connection to the next article (on-prem to cloud and then cloud to cloud).
We have reached the end of the first stage of our journey in Cloud Disaster Recovery. After defining the macro concepts and understanding the dynamics, it is time to delve into the implementation of DR techniques in complex business scenarios.
We will start by exploring the best DR techniques for hybrid on-prem to cloud contexts in the next article, and then discuss DR for Business Continuity in the Cloud-to-Cloud context in the third article of our mini-series.
Are you ready? See you in 14 days on Proud2beCloud!
Proud2beCloud is a blog by beSharp, an Italian APN Premier Consulting Partner expert in designing, implementing, and managing complex Cloud infrastructures and advanced services on AWS. Before being writers, we are Cloud Experts working daily with AWS services since 2007. We are hungry readers, innovative builders, and gem-seekers. On Proud2beCloud, we regularly share our best AWS pro tips, configuration insights, in-depth news, tips&tricks, how-tos, and many other resources. Take part in the discussion!

