
When Serverless runs on servers: new options for AWS Lambda and AWS Fargate with Managed Instances
04 March 2026 - 13 min. read
Damiano Giorgi
DevOps Engineer


In this series of articles, we will describe how to properly create and structure a self-service Data Platform for data democratization analytics on AWS. We will start with data ingestion and storage and then move through processing tools to create valuable data for analytics, visualizations, and reporting. Moreover, we will focus on data governance, discoverability, and collaboration, with an eye on security and access control.
Follow this article to learn how to democratize data access through your self-service Data Platform. Using AWS LakeFormation, ensure data governance and properly structure data, access, and visibility. Don’t forget to keep an eye on the website for part 3!
This article is a sequel to the description of data platforms, and related data pipelines, building on top of those concepts. If you are still trying to familiarize yourself, or maybe you just need a refresher on these concepts, here is part 1
Ingest your data sources inside S3 buckets and register data locations inside AWS LakeFormation. Catalog data with databases, tables, and columns. Define and associate LF-Tags to these catalog resources to perform attribute-based access control (ABAC). Define roles and grant them tag-based permissions to enable data access. Create an administrator with grantable permissions on specific areas and use tags for data discoverability to democratize and achieve self-service data access.
In today's data-driven world, organizations face a critical paradox: they are swimming in vast oceans of data, although most struggle to effectively utilize this valuable resource.
Traditional data management approaches tended to organize data in separated, disconnected, structures, like siloes. In these approaches, each silo is usually accessible only by its own technical department, creating several problems along the way.
The challenges of data democratization extend beyond technical limitations. This silos separation creates complex barriers that prevent analysts from widespread data access, like submitting time-consuming requests to IT or data teams for even the most basic data access. Users operate with incomplete information, having a very hard time seeing the “bigger picture”, and the potential competitive advantage of data-driven decision-making remains unrealized.
Many companies find themselves trapped in a cycle of manual access management, where data access requests require multiple approvals, complex permission configurations, and ongoing maintenance. This not only creates a significant administrative burden but also slows down the potential for innovation.
The data lake architecture helps solve this challenge by concentrating all data into a single place. Everyone needing access to data knows where to look. But not all the glitter is gold! Aggregating all data into a single place creates a new, yet different, challenge: user access management. Even though now everyone can, potentially, have access to data, is it safe?
Organizations must simultaneously balance two competing priorities: enabling broad data access while maintaining rigorous data governance and security protocols. The risk of exposing sensitive information, coupled with compliance requirements like GDPR, CCPA, and industry-specific regulations, creates a significant overhead in managing data permissions.
Here is where AWS LakeFormation can become a very handy tool!
AWS Lake Formation is a fully managed service that simplifies the creation, security, and management of data lakes.
At its core, the service simplifies the traditionally complex and time-consuming process of consolidating data from multiple sources into a unified and secure repository, the data lake, within a few days instead of months/year. Unlike traditional data management approaches that require extensive manual configuration and complex infrastructure setup, AWS LakeFormation automates critical tasks such as data ingestion, metadata cataloging, and access control. It is a centralized platform that abstracts from technical complexities, allowing data engineers, analysts, and business leaders to focus on what really matters: extracting insights and real value from data.
Moreover, AWS LakeFormation provides robust governance and security capabilities, essential features for data governance in data-driven enterprises. The service offers granular, attribute-based access controls that enable organizations to define precise data access policies at the database, table, column, and even row levels. This means businesses can implement fine-grained security mechanisms that ensure sensitive information is protected while still being able to achieve data democratization. By seamlessly integrating with other AWS services like Amazon S3, AWS Glue, and Amazon Athena, AWS LakeFormation creates a comprehensive ecosystem that supports the entire data lifecycle, from raw data ingestion and transformation to analysis and visualization. Its ability to centralize metadata management, automate data discovery, and provide consistent security across diverse data sources makes it a pivotal tool for enterprises seeking to leverage their data assets efficiently and securely.
Now that we’ve described the challenges and the toolset, let’s dirty our hands and put it into action!
If you read the first of this series of articles, you already know what we are working with, but to get everyone on the same page, here is a very brief overview of the setup.
Acting as a data engineer for a fictional company that helps its customers increase their revenues, you created a data platform following the standard medallion architecture. You developed ingestion and transformation logic to gather data and move it through the increasingly refined layers of the data platform.
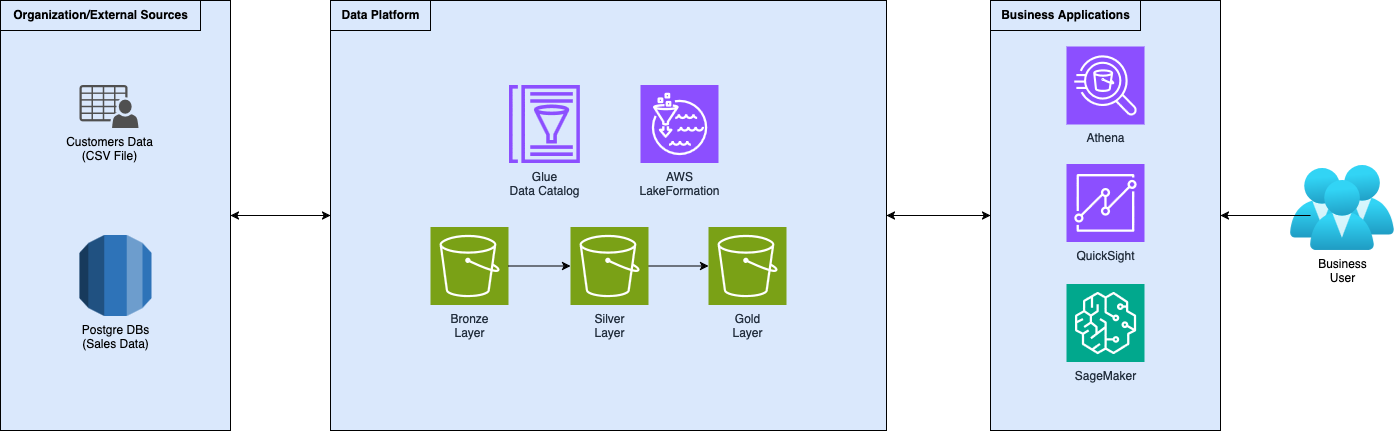
The company now asks you to govern the data platform, making data accessible to internal teams and customers. Customers just want to see and query their data. Meanwhile, internal teams need to visualize data and use it to train machine learning models to help customers achieve their goals. Additionally, you need to keep an eye on data access and security: customers must only see their data! Moreover, customers' data contains PII, which is not useful for internal teams and should not be visible to them.
We already have all raw data ingested inside the bronze layer bucket; however, here is a quick tip that may be useful for some readers who are trying to implement ingestion.
AWS LakeFormation offers blueprints to ingest data from relational databases, CloudTrail, and load balancer logs. Blueprints are pre-defined CloudFormation templates that create all the needed resources to perform ingestion from your sources. Under the hood, it creates a Glue workflow, composed of Glue jobs and crawlers that ingest data inside your S3 buckets and update the Glue Data Catalog.
First, we need to make AWS LakeFormation aware of the assets composing our data lake. To do so, we need to register the S3 locations. You can register buckets or specific paths inside them. Following the medallion architecture, we created 3 buckets:
A suggestion here is to structure data inside the buckets keeping in mind who needs to access which data and what kind of queries need to be issued against that data. This will help you to easily structure permissions for accessing data and make queries fast and efficient.
In our example, we structured data by dividing it among the business units that need to access them. In our case: marketing and sales.
We perform this operation for all the buckets and paths that we defined.
Now that we have defined the components of our data lake, it’s time to catalog data. You need to create databases on top of data lake locations. The database allows us to create logical structures, tables, and views on the data lake so that users can easily access and query data via SQL.
Since we are doing a test example with very few tables, we only created a database for every layer of the medallion architecture. The idea here is to showcase data access management using AWS LakeFormation, therefore, we divided data into two levels:
In part one of this series of articles, we built the data pipeline that performs ingestion and refinement through the various layers of the data platform, so we already have data in place. We leverage Glue Crawlers to automatically discover and catalog data inside the Glue Data Catalog, which is integrated with AWS LakeFormation. After running the crawlers, here are the tables we will work on:
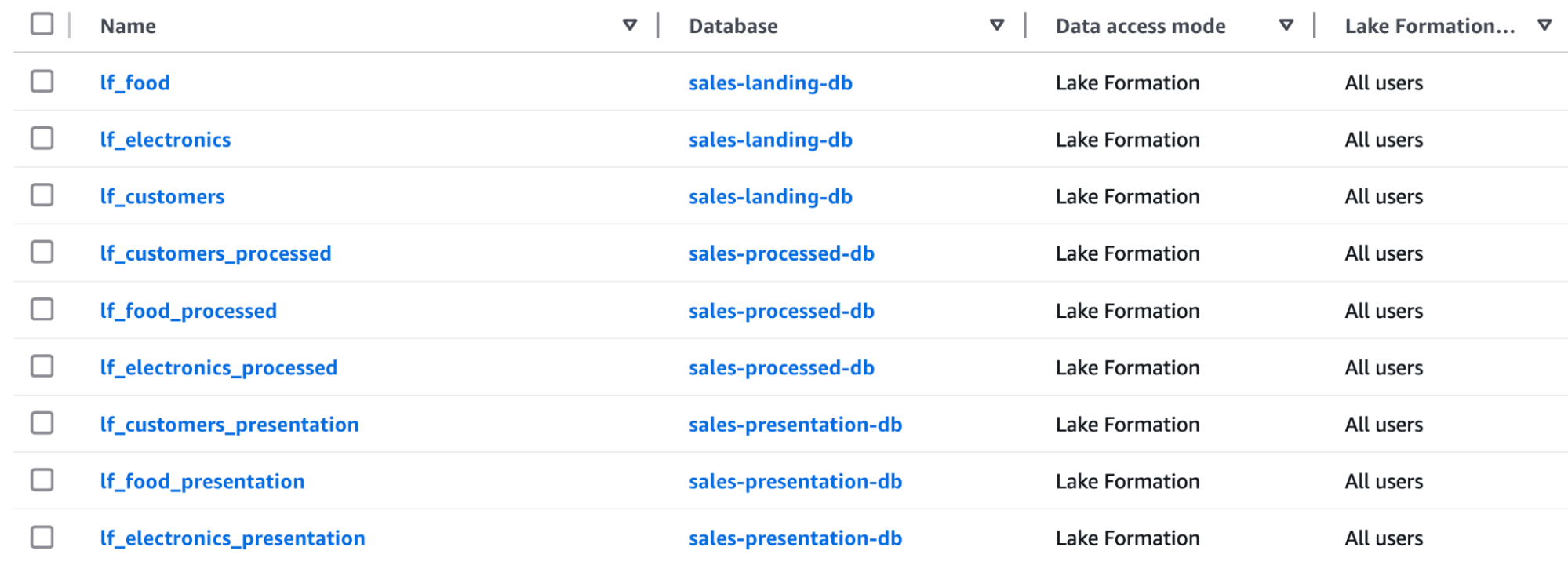
Another quick tip: spend some time adding metadata and descriptions to your databases, tables, and columns to improve discoverability. For example, you can add business descriptions so that business users can use their own terminology to find the right data, dramatically reducing the time spent on data discovery.
Another best practice is to associate tags to data inside AWS LakeFormation. LF-Tags (Lake Formation Tags) are key-value pairs that you can associate with databases, tables, and columns to describe features like the sensitivity of the data, the business domain, or any other relevant entity that is valuable to you.
We will use these tags later for implementing attribute-based access control (ABAC), a far more scalable approach than traditional role-based access control.
Now that we have all the sources in our data lake, let’s start building the foundations to perform data lake administration and grant data access in an easy way.
As mentioned before, we start by defining our tag strategy with LF-Tags to implement attribute-based access control (ABAC) and manage data access at scale. This step is crucial for data democratization since we will use these tags to both let users self-discover data and grant access to that data.
In our example, we developed this simple strategy:
After creating LF-Tags, with their allowed value sets, you can start assigning them to databases, tables, or views, and even to specific columns. Remember that LF-Tags are propagated in lower-level structures, therefore, all tags associated with a database will be associated with all its tables. Likewise, all tags associated with a table/view will be associated with all its columns.
The real power of LF-Tags, with respect to traditional approaches, appears when implementing complex access patterns, being able to follow the principle of least privilege with extraordinary precision. Data stewards can create tag-based access policies that automatically grant permissions to users who possess matching tags in their LF-Tag expressions. Few quick examples here based on our test data:
This approach drastically reduces operational overhead as the data lake grows. As new datasets are added, their administrators need only to apply appropriate tags and correct access controls will be enforced by design. Similarly, when a new user joins, data lake administrators just need to assign the appropriate LF-Tag expressions, and access to all relevant data inside the organization will be granted.
Data is now categorized with tags, and we have developed tag policies to define how to access it. It’s time to define the entities that will access data and start granting permissions.
First, let’s define the entities that will access our data.
The idea here is to create roles that reflect business functions inside the organization. This approach is very effective since as a new person joins the project, it simply needs to be assigned to the appropriate role rather than requiring custom permission configurations, significantly reducing administrative overhead.
In our case, we defined:
The core idea is to delegate database administration to the administrative roles so that they can grant permissions independently, promoting a democratized approach to data.
Finally, it’s time to grant permissions!
Now that we have placed all the necessary pieces, we have the foundation to achieve self-service data access.
Having all data structured and organized in AWS LakeFormation, with the content properly described via tags, in a very precise way, up to the column level, allows users to easily search for needed data and start extracting value from it.
As AWS LakeFormation administrators, we start by delegating data administration of every organization’s area to local administrators. As mentioned before, we define two administrators, one for the marketing area and one for sales, using the LF-Tag expressions:
With these simple expressions, we select all databases, tables, and columns that are tagged with those LF-Tag values.
Since we are creating administrator roles, we grant super permissions on both databases and tables. Moreover, very importantly, we also allow grantable read permissions to delegate data access administration to these roles so that they can self-serve their team.
Here, we see the real power of the AWS LakeFormation permission model, which, instead of IAM policies, provides data-specific controls that operate independently from the underlying storage layer. This is a crucial advantage since data access policies remain consistent regardless of how users access the data. Whether it is a query on a table through Athena, an analysis with SageMaker, or a dashboard using QuickSight, AWS LakeFormation permissions remain the same and apply consistently.
Area administrators’ can now see all the tables associated with their respective areas inside the organization. Now, to complete the example, we can use the sales area administrator to grant access to food sales data to its team, represented by the data analyst role. By doing so, the analyst will be able to see and use food sales data to perform analysis and create dashboards for visualization.
We have finally democratized data access. Users can now freely discover data using tags and access it!
Before wrapping up, let's have a look at AWS LakeFormation monitoring and auditing features.
AWS LakeFormation offers a centralized dashboard that security teams can use to review all data access events. This centralization enables more effective governance, simplifies compliance, and faster audit responses.
Here is an example image of the dashboard:
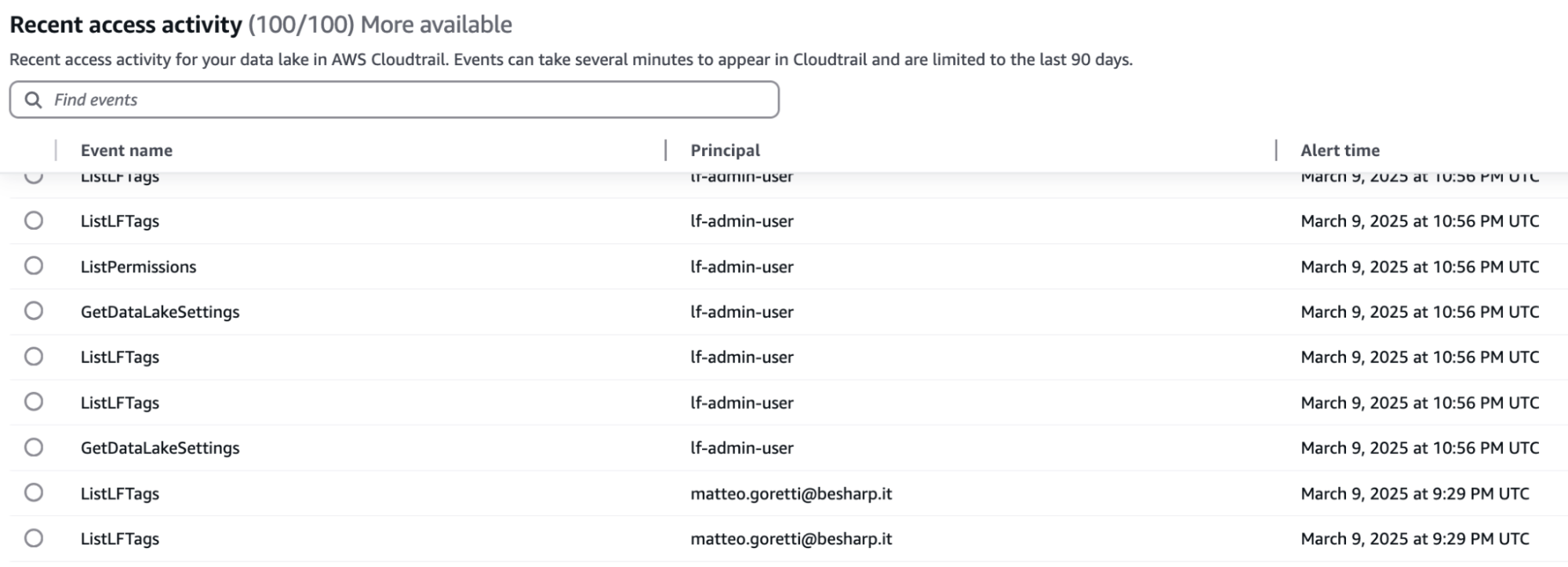
At first sight, the dashboard reports the event alongside the user and the time of the event. Each event has a detailed description, which is its log inside CloudTrail.
In this article, we've explored how AWS LakeFormation can transform data access in organizations through a self-service data platform.
From the setup, registering data locations, comprehensive data cataloging with business metadata, and LF-Tags for attribute-based access control, organizations can achieve true data democratization while maintaining robust security.
The power of AWS LakeFormation lies in its ability to define granular permissions at database, table, column, and row levels, allowing administrators to delegate access control to area-specific data stewards. This approach significantly reduces administrative overhead while ensuring users can discover and access only the data they need.
Through proper implementation of role-based structures aligned with business functions and consistent permission models across all AWS analytics services, AWS LakeFormation creates a foundation for data-driven decision-making across the enterprise.
Now that you know how to democratize data with AWS LakeFormation, in the next chapter of this series of articles, we will explore services that build on top of it, like DataZone.
Have you ever tried to democratize data access on your own? Let us know in the comments!
Proud2beCloud is a blog by beSharp, an Italian APN Premier Consulting Partner expert in designing, implementing, and managing complex Cloud infrastructures and advanced services on AWS. Before being writers, we are Cloud Experts working daily with AWS services since 2007. We are hungry readers, innovative builders, and gem-seekers. On Proud2beCloud, we regularly share our best AWS pro tips, configuration insights, in-depth news, tips&tricks, how-tos, and many other resources. Take part in the discussion!


