
Enabling enterprise Telemetry on AWS: Handling massive data backfills using ECS and Databricks wi...
17 June 2026 - 1 min. read
Keidi Xhafa


Decoupling complex workloads is a practice that people sometimes undertake without a clear understanding of the advantages and risks. We frequently hear about modular applications built with microservices, where you can decide what to activate or deactivate without any impact on the other parts or that can scale infinitely.
However, what about monitoring? What about the risks of ending up working in a messy codebase that, for the sake of scaling and all the other wonderful advantages, ruins the developer experience? Here's a very good article written by my colleague and friend, Damiano, that delves into the considerations everyone should make when working with microservices.
Today, we'll discuss two decoupling strategies, their benefits, their challenges, and also when one is better than the other. The focus will be on AWS services because there are many options (Amazon SQS, EventBridge, SNS), but these considerations can also be applied to other tools.
The name is quite self-explanatory: our workload has a single entry point for exchanging and reading messages. Every event producer forwards its payload to that queue, where multiple consumers are listening. This approach is often dismissed as too chaotic since the queue holds unrelated messages, and it doesn't align with a "microservice-oriented" mindset. While this might be true, the benefits exist and should not be overlooked.
Imagine we are working on an application where we have many event producers and just a few processes that process those messages. When the number of event types is small, a single queue approach is really easy to implement, monitor, and extend. Every time a new producer is created, it just has to send messages to the only existing queue. On the other hand, consumers will need to filter messages by their type to deal only with events within their competence, which requires a bit more logic to implement.
This is a much simpler approach to building a decoupled application, but remember, we don't have to start with complexity. Just be aware of spikes in traffic your queue might be subjected to; having too many messages going through the same tunnel could create congestion.
While the single queue approach is ideal for small workloads, a more complex application with more people working on it is easier to maintain if every microservice has its own queue. This allows more granular monitoring because it can be done at a microservice level, and messages going through the queue will follow a standard. This strategy allows also the creation of a more granular management of the permissions: if you want to set up communication between two microservices, you’ll need to grant access to the producer to produce events inside the consumer’s queue.
Be aware that whenever one of your microservices produces events for another microservice, you create a dependency link, therefore creating an antipattern. Microservices should be independent from each other, have their own database, and computational resources, and shouldn’t communicate with each other. This is the theory, of course; in the real world, we need to analyze every single case to understand if we should stick to the common patterns or if deviating from a standard can help us create easier-to-understand workflows.
Anyway, a good strategy for handling complex workflows where multiple microservices have to be called can be setting up state machines that handle these events forwarding, output parsing, and decision-making in a controlled way. This makes our application easy to debug, monitor, and extend. If you make your microservices really independent from each other, you’ll also be able to test them without creating side effects.
We’ve already introduced the monitoring topic twice in this article, let’s analyze it better now.
When working with microservices, we usually create asynchronous communications between them, and it’s often hard to keep track of the lifecycle of a specific event: if something goes wrong, we need to be able to understand which process failed, how we should remediate the error, and how we can prevent side effects that can impact on the user experience. This is a topic that DevOps need to deeply analyze in the first stage of the project.
On AWS, tools like CloudWatch dashboards can be really helpful to gain insights about how the workload is behaving, but it has to go further than that. Of course, having the possibility to monitor the number of messages inside the queue or the number of events that failed to be processed is important to understand where our single points of failure are and where we should make considerations about scaling, but we still need something that helps us monitor the workload at the application level.
Here’s where AWS X-Ray can help us: AWS X-Ray allows us to trace and analyze requests as they travel through our application. This provides us with a detailed view of the application's behavior, enabling us to identify where bottlenecks occur and which services cause delays. This end-to-end view of the workflow allows us to identify and resolve issues more effectively. With X-Ray, we can get useful metrics such as the time our microservice spent doing something (like an HTTP request) or which other microservices have been called to process an event.
When we talk about decoupling workloads, the first AWS service that comes to mind is Amazon SQS. It was built exactly with this purpose in mind: producers can put their events inside a queue while consumers will poll on that queue to see if there are some messages to process. Amazon SQS offers several features that can be useful for our goal, like dead-letter queues for storing unprocessed messages, long polling to prevent the consumer side from flooding our queue with requests, and FIFO queues if we need to process our events in the same order they were produced.
Amazon SQS is a great service, but sometimes we find features in other AWS services that can fit our needs better. An AWS service I particularly like is Amazon EventBridge. With Amazon EventBridge, we can register multiple targets to be notified whenever a message is published in an Event Bus, but we can also filter these messages by specifying patterns to forward them to the correct target. This is really useful if we are building a single queue approach!
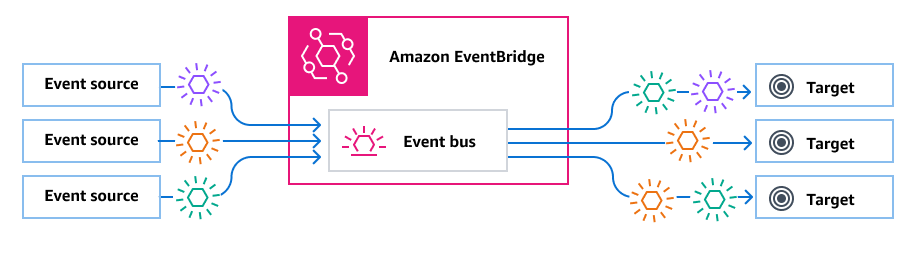
Image source: AWS Documentation
I love two other Amazon EventBridge features: archive/replay and pipes.
Archives are spaces where we can store events that match a pattern; they have a retention period and can be replayed later on. Replaying events helps us test our microservices to ensure we haven’t added any regression while working on a new feature, but we can also reprocess previously failed events.
Events are replayed in the exact order they were received in the first place.
EventBridge Pipes is a feature that was released in December 2022 and helps us create a small business logic to further filter our events or enrich them with other information. The enrichment feature is something I really love, and can be achieved easily with a Lambda function, but also with a Step Function or an HTTP request. I think Lambda is the most suited service for this purpose since I want the enrichment to be as fast as possible. Pipes come with a cost, and they should be considered when planning the architecture, especially when we expect tons of events to be processed by them!
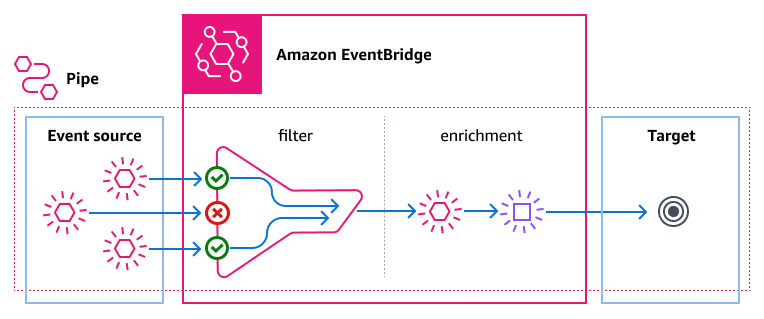
Image source: AWS Documentation
Recently I used a decoupling pattern in a project where I had to build a REST API that, when called, does some logic and queries on the database and, depending on the query result, makes some API calls to external services that implement different protocols. What I did was simply to split the whole logic into two macro-categories, each owned by a Lambda function.
The first Lambda function processes the payload received through the API call, queries the database, and fetches all the parameters. Finally, it creates a payload that sends it to an EventBridge bus, and along the parameters, there is also a property that specifies the type of third-party service that needs to be called.
Then I created a set of Lambda functions, one per third-party service, all of which are registered as targets to the same bus with a pattern that matches only their type of service. These functions only take care of handling the business logic for their third party service.
By doing so, I was able to create multiple smaller and easy-to-maintain Lambda functions that take care only of what they need to do, with a producer Lambda function that always publishes messages to the same AWS service and a set of consumer Lambda functions, all of them similar regarding the general configuration but that differ on the business logic.
Patterns were created to make our lives simpler, preventing us from reinventing the wheel every time.
They are a well-known standard that every DevOps with a bit of experience should know, since they aim to solve real problems.
At the same time, we have to be focused on our goal: I always think that the best approach is to start simple and make things complex later on... if needed. I used both strategies in the past, choosing one over the other depending on the complexity and criticality of the project I was working on.
What's your experience about this topic? How do you handle decoupling? Let us know in the comments!
Proud2beCloud is a blog by beSharp, an Italian APN Premier Consulting Partner expert in designing, implementing, and managing complex Cloud infrastructures and advanced services on AWS. Before being writers, we are Cloud Experts working daily with AWS services since 2007. We are hungry readers, innovative builders, and gem-seekers. On Proud2beCloud, we regularly share our best AWS pro tips, configuration insights, in-depth news, tips&tricks, how-tos, and many other resources. Take part in the discussion!


