
Quando il Serverless “gira” sui server: nuove opzioni per AWS Lambda e AWS Fargate co...
04 Marzo 2026 - 14 min. read
Damiano Giorgi
DevOps Engineer


 MongoDB è un database NOSQL documentale immediato da configurare e da utilizzare e sta avendo una grandissima diffusione nei nuovi progetti di sviluppo. In questo articolo vedremo come sia possibile creare un sistema di self healing per i cluster di Mongo creati su AWS in modo da prevenire un possibile downtime.MongoDB consente di creare un cluster distribuito in alta affidabilità tramite i Replica Sets e lo Sharding:
MongoDB è un database NOSQL documentale immediato da configurare e da utilizzare e sta avendo una grandissima diffusione nei nuovi progetti di sviluppo. In questo articolo vedremo come sia possibile creare un sistema di self healing per i cluster di Mongo creati su AWS in modo da prevenire un possibile downtime.MongoDB consente di creare un cluster distribuito in alta affidabilità tramite i Replica Sets e lo Sharding: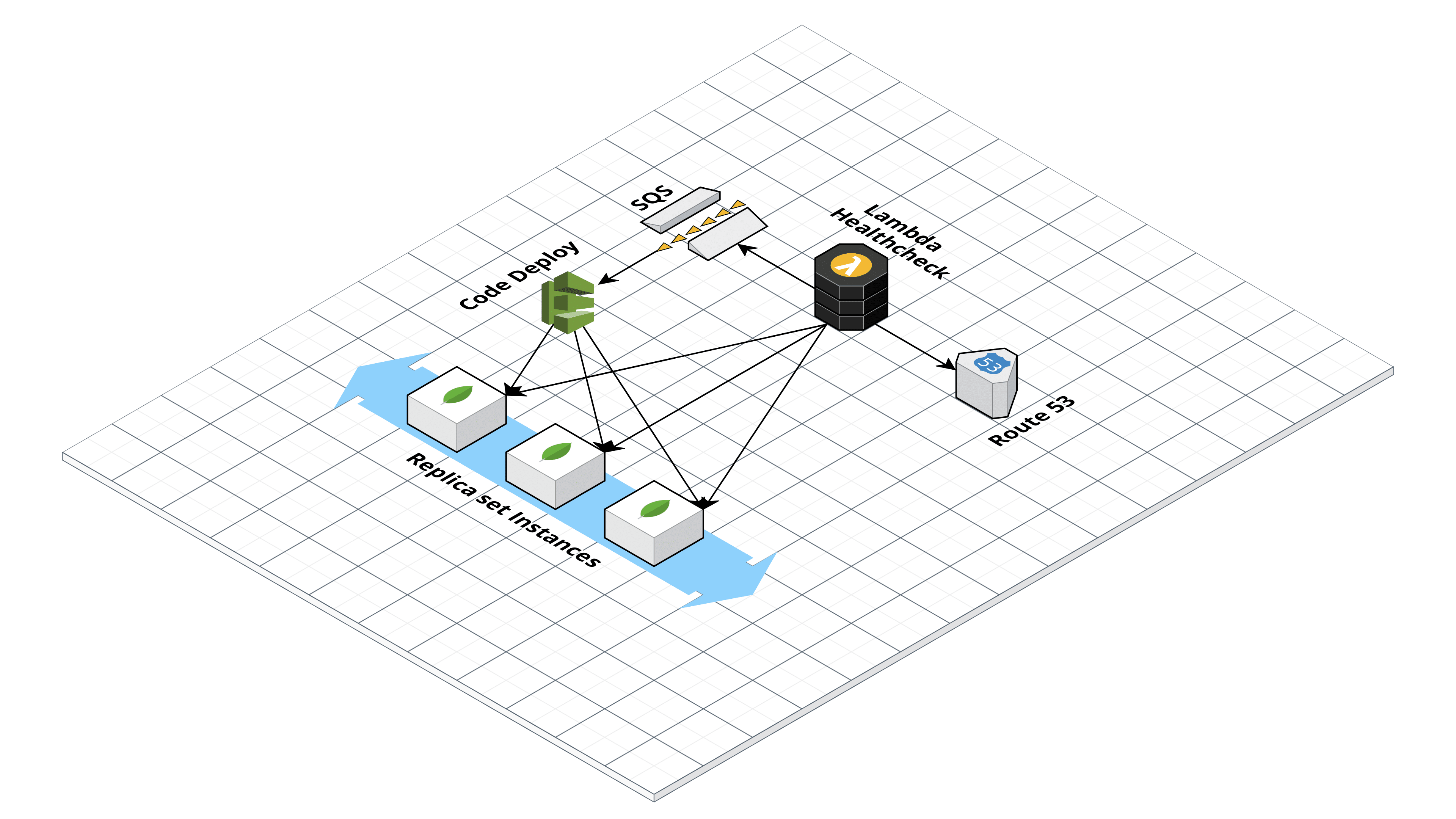
openssl rand -base64 756 > <path-to-keyfile> chmod 400 <path-to-keyfile>Il keyfile è una forma minimale di sicurezza ed è accettabile solo su una rete sicura (subnet private in VPC), per l’ambiente di produzione è comunque preferibile usare un certificato x.509. Il file di configurazione di MongoDB sarà simile al seguente:
storage: dbPath: /mnt/mongo/data journal: enabled: true systemLog: destination: file logAppend: true path: <logs-path> security: keyFile: <keyfile-path> replication: replSetName: test-rs net: port: 27017 bindIpAll: trueLa creazione iniziale del cluster MongoDB può essere completamente automatizzata usando CloudFormation, oppure può essere eseguita manualmente utilizzando l’ami appena creata e uno script di configurazione da eseguire sulle singole macchine del cluster.Una delle macchine va configurata inizialmente per essere il master e inizializzare il Replica Set. Per fare ciò è necessario prima avviare Mongo senza i campi security e replication nel file di configurazione e poi creare un utente admin col comando:
db.createUser({user: "<ADMIN_USER>", pwd: "<PWD>", roles:[{role: "root", db: "admin"}]});A questo punto Mongo va riavviato col file di configurazione contenente security e replication. Dopo aver acceso anche le altre macchine, che inizialmente saranno repliche, è necessario creare degli A name su una private hosted zone di R53 per tutte le macchine del replica set. Nelle configurazioni della VPC è inoltre necessario selezionare le opzioni enableDnsHostnames e enableDnsSupport per attivare la risoluzione dei DNS interni di R53.Fatto ciò è finalmente possibile connettersi in SSH al master e tramite la cli di mongo attivare il replica set col comando:rs.initiate( { _id : "test-mongo-rs", members: [ { _id: 0, host: "mongodb-1.test.it:27017" }, { _id: 1, host: "mongodb-2.test.it:27017" }, { _id: 2, host: "mongodb-3.test.it:27017" } ] });Ora che il Replica Set è configurato e funzionante è giunto il momento di occuparci della parte di self healing.
import boto3 from pymongo import MongoClient sqs = boto3.client('sqs') mongoserver_uri = os.environ['MONGO_URI'] hostzone = os.environ['ZONE_ID'] mongo_connection = MongoClient(mongoserver_uri) dns_aws = boto3.client('route53') ec2 = boto3.resource('ec2') rs_status = mongo_connection.admin.command('replSetGetStatus')Tutti i nodi non funzionanti avranno “health”: 0. Per evitare falsi positivi abbiamo configurato il codice in modo da ripetere il controllo varie volte in un intervallo di tempo di un minuto. Se entro questo intervallo il nodo non ritorna healty la Lambda scrive un messaggio su una coda SQS contenente il DNS name della macchina fallita e un timestamp. Fatto questo il codice provvederà a de-registrare la macchina fallita dall’Autoscaling Group, se questa non è già stata terminata, utilizzando boto3:
autoscaling = boto3.client('autoscaling') response = autoscaling.detach_instances( InstanceIds=[ 'string', ], AutoScalingGroupName='mongo-autoscaling', ShouldDecrementDesiredCapacity=False )Per evitare esecuzioni multiple la lambda è configurata per mandare il messaggio su sqs e deregistrare l’istanza solo se la coda SQS è vuota (ApproximateNumberOfMessages = 0).Una volta preparata la lambda è il momento dell’ultimo passaggio: la configurazione di CodeDeploy che ha il compito di configurare le nuove istanze al momento dell’accensione da parte dell’ autoscaling group. Iniziamo col creare una nuova applicazione nella dashboard di CodeDeploy e un nuovo deployment group mettendo come target l’autoscaling group appena creato. CodeDeploy esegue sulla macchina una serie operazioni di script configurabili dall’utente, definite in un file chiamato appspec.yml che deve essere salvato in un bucket S3 insieme agli script e ai file che devono essere trasferito e/o eseguiti sulla macchina.La struttura del file è la seguente:
version: 0.0 os: linux files: - source: /content destination: /home/ubuntu hooks: ApplicationStop: - location: scripts/applicationstop.sh timeout: 300 runas: root BeforeInstall: - location: scripts/beforeinstall.sh timeout: 300 runas: root AfterInstall: - location: scripts/afterinstall.sh timeout: 300 runas: root ApplicationStart: - location: scripts/applicationstart.sh timeout: 300 runas: root ValidateService: - location: scripts/validateservice.sh timeout: 300 runas: rootLa struttura della cartella da caricare su s3 è la seguente e da utilizzare come input di codedeploy è la seguente:
content/ mongod.conf mongo-keyfile scripts/ afterinstall.sh applicationstart.sh applicationstop.sh beforeinstall.sh validateservice.shNel nostro caso la cartella content contiene il keyfile e il file di configurazione di Mongo mentre la cartella scripts contiene gli script bash che si occupano di configurare la nuova istanza. In particolare gli script devono leggere dalla coda SQS il messaggio contenente il DNS name della macchina fallita, configurare Mongo sulla macchina appena accesa, tramite la CLI di MongoDB riconfigurare il Replica Set per usare il nuovo nodo e quindi avviare il servizio di mongo.Non appena un'istanza fallisce (oppure il processo di mongo diventa unresponsive) si innesca dunque la seguente catena di eventi:


