
Telemetria Enterprise su AWS: Gestire backfill di dati massivi con ECS e Databricks senza far esp...
17 Giugno 2026 - 2 min. read
Keidi Xhafa


 L’utilizzo di Pipeline per il deploy automatico del codice è ormai una feature quasi imprescindibile di ogni progetto di sviluppo in Cloud, in quanto il concetto stesso di architettura scalabile richiede che le macchine virtuali (o i container), che vengono avviati sul Cloud per gestire i picchi di traffico, utilizzino la versione più aggiornata del codice. Inoltre, la creazione di una pipeline automatica libera i DevOps dalla gestione manuale di AMIs e Docker images, oltre a eliminare la possibilità di “errori umani” in fase di deploy.AWS mette a disposizione dei DevOps uno strumento molto potente per la creazione di Pipeline automatiche: AWS CodePipeline. Questo servizio totalmente managed funziona come un orchestrator per una pipeline di CI/CD con funzionalità analoghe a quelle offerte da altri servizi come Jenkins che però vanno installati su un'istanza EC2 e, pertanto, oltre a non essere in alta affidabilità, richiedono un effort significativo di configurazione e manutenzione.Il flusso più comune di una AWS CodePipeline è composto da tre step:
L’utilizzo di Pipeline per il deploy automatico del codice è ormai una feature quasi imprescindibile di ogni progetto di sviluppo in Cloud, in quanto il concetto stesso di architettura scalabile richiede che le macchine virtuali (o i container), che vengono avviati sul Cloud per gestire i picchi di traffico, utilizzino la versione più aggiornata del codice. Inoltre, la creazione di una pipeline automatica libera i DevOps dalla gestione manuale di AMIs e Docker images, oltre a eliminare la possibilità di “errori umani” in fase di deploy.AWS mette a disposizione dei DevOps uno strumento molto potente per la creazione di Pipeline automatiche: AWS CodePipeline. Questo servizio totalmente managed funziona come un orchestrator per una pipeline di CI/CD con funzionalità analoghe a quelle offerte da altri servizi come Jenkins che però vanno installati su un'istanza EC2 e, pertanto, oltre a non essere in alta affidabilità, richiedono un effort significativo di configurazione e manutenzione.Il flusso più comune di una AWS CodePipeline è composto da tre step: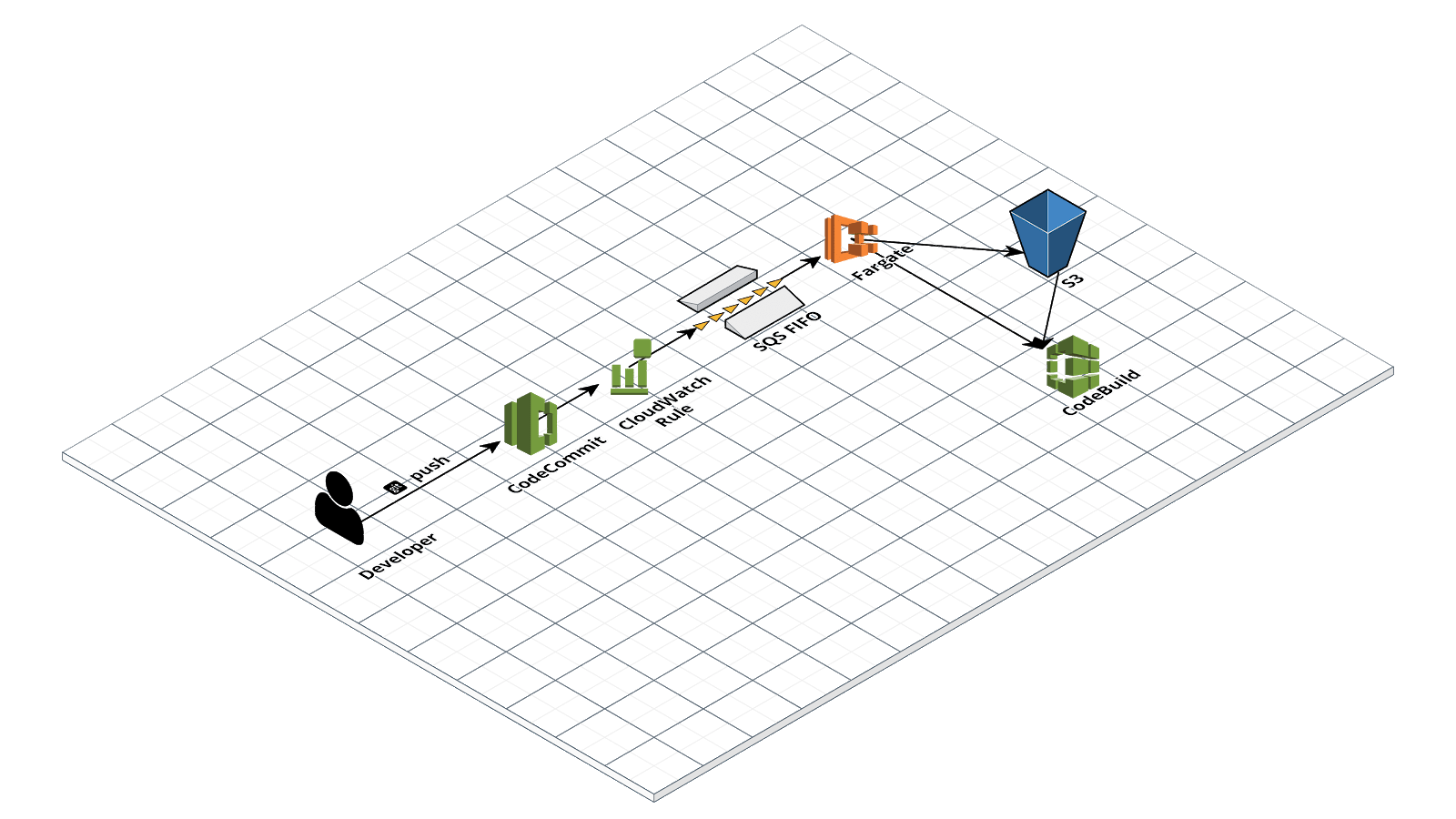
{ "source": [ "aws.codecommit" ], "detail-type": [ "CodeCommit Repository State Change" ], "resources": [ "arn:aws:codecommit:eu-west-1:<ACCOUNT_ID>:<REPOSITORY>", ... ], "detail": { "event": [ "referenceCreated", "referenceUpdated" ] } }La coda SQS FIFO contiene perciò i messaggi corrispondenti agli eventi di push del codice sul repository e viene consumata dai container Fargate. Per evitare che messaggi corrotti possano venire ri-processati all’infinito, abbiamo aggiunto una dead letter queue dove i messaggi vengono trasferiti dopo due tentativi di lettura falliti. Una volta avviato dalla CloudWatch Rule, il container Fargate legge i messaggi dalla coda, esegue il pull del commit dal repository CodeCommit, salva il bundle compresso del codice su s3 ed infine lancia AWS CodeBuild coi parametri corretti.Il container Docker è stato creato usando il Dockerfile:
FROM ubuntu:16.04 RUN apt-get update RUN apt-get install wget -y RUN apt-get install numactl -y RUN apt-get install jq -y RUN apt-get install zip -y RUN apt-get install git -y RUN apt-get install software-properties-common -y RUN add-apt-repository ppa:jonathonf/python-3.6 -y RUN apt-get update RUN apt-get install python3.6 -y RUN wget https://bootstrap.pypa.io/get-pip.py RUN python3.6 get-pip.py RUN pip3.6 install awscli --upgrade RUN pip3.6 install boto3 RUN mkdir /pipeline_source WORKDIR /pipeline_source ADD ./codecommit_source.sh /pipeline_source/codecommit_source.sh RUN chmod +x /pipeline_source/codecommit_source.sh CMD /pipeline_source/codecommit_source.shCome si può vedere sono richiesti solo pacchetti standard di bash, oltre alla AWS CLI. Lo script codecommit_source.sh viene avviato al momento dell’accensione del container, ed esegue la logica appena descritta.Un codecommit_source.sh di esempio è mostrato qui sotto:
#!/bin/bash set -Eeuxo pipefail MESSAGE=$(aws sqs receive-message --queue-url https://sqs.eu-west-1.amazonaws.com/<account-id>/custom-codecommit-events.fifo --wait-time-seconds 20) RECEIPT_HANDLE=$(echo $MESSAGE | jq -r '.Messages | .[] | .ReceiptHandle') aws sqs delete-message --queue-url https://sqs.eu-west-1.amazonaws.com/<account-id>/custom-codecommit-events.fifo --receipt-handle $RECEIPT_HANDLE if [ -n "$MESSAGE" ] then EVENT=$(echo $MESSAGE | jq -r '.Messages | .[] | .Body | fromjson') REPOSITORY_NAME=$(echo $EVENT | jq -r '.detail | .repositoryName') COMMIT_ID=$(echo $EVENT | jq -r '.detail | .commitId') BRANCH_NAME=$(echo $EVENT | jq -r '.detail | .referenceName') REPO_URL=https://git-codecommit.eu-west-1.amazonaws.com/v1/repos/$REPOSITORY_NAME git config --global credential.helper '!aws codecommit credential-helper $@' git config --global credential.UseHttpPath true git clone --depth 10 --branch $BRANCH_NAME $REPO_URL cd $REPOSITORY_NAME git checkout $COMMIT_ID rm -rf .git zip -r ../$COMMIT_ID.zip . cd .. rm -rf $REPOSITORY_NAME if [ -s $COMMIT_ID.zip ] then CODEBUILD_PROJECT=$REPOSITORY_NAME if [ $BRANCH_NAME != "test" ] && [ $BRANCH_NAME != "develop" ] && [ $BRANCH_NAME != "staging" ] then aws s3 cp $COMMIT_ID.zip s3://$CODE_BUCKET/$REPOSITORY_NAME/$BRANCH_NAME/$COMMIT_ID.zip echo s3://$CODE_BUCKET/$REPOSITORY_NAME/$BRANCH_NAME/$COMMIT_ID.zip aws codebuild start-build --project-name $CODEBUILD_PROJECT --environment-variables-override name=COMMIT_ID,value=$COMMIT_ID,type=PLAINTEXT --source-type-override S3 --source-location-override $CODE_BUCKET/$REPOSITORY_NAME/$BRANCH_NAME/$COMMIT_ID.zip --artifacts-override type=NO_ARTIFACTS fi fi else echo "no message in queque" fiInfine, chi gestisce il source code dovrà aver cura di creare/modificare il buildspec in modo da salvare gli output della build su S3 con un nome facilmente leggibile.La soluzione qui riportata può essere facilmente modificata per funzionare anche in caso di account multipli. Ad esempio possono essere presenti due account: il primo account (“master”) contenente l’ambiente di produzione e i repos mentre il secondo gli ambienti di staging/development e le pipeline. Per far ciò è necessario aggiungere un ruolo all'account “master” che possa essere assunto da staging in modo da fare il pull dei repository. Infine sarà anche necessario configurare event bus su entrambi gli account in modo da condividere i messaggi di prod relativi ai repo con l’account di sviluppo.Per concludere AWS CodePipeline è uno strumento molto potente, ma per alcuni casi di uso non è sufficiente e va perciò affiancato a soluzioni custom come quella proposta che sono facilmente configurabili usando l’ampia suite di servizi messi a disposizione da AWS.Vuoi raccontarci di una tua soluzione di CD/CI innovativa o avere ulteriori infomazioni su quella proposta in questo articolo? Non esitare a commentare e/o a contattarci!


