

Enabling enterprise Telemetry on AWS: Handling massive data backfills using ECS and Databricks wi...
17 June 2026 - 1 min. read
Keidi Xhafa
 In the last few years, Las Vegas has become the reference point for AWS Cloud events. We have seen first-hand re:Invent grow from 6,000 participants in 2012 to over 40,000 last year. An immense event, in which it has become difficult to simply choose the sessions in which to participate! It must also be for this reason that this year, AWS has decided to complement their main event with some conferences with a more specific focus, the first of which, the AWS Re:MARS, was created around the hottest topics of the moment: Machine Learning, Automation, Robotics and Space.beSharp - obviously - could not miss it.Many big names were present as keynote speakers: Jeff Bezos, Werner Vogels, Coursera co-founder Andrew Ng, IRobot CEO and founder Colin M. Angle and ... Robert Downey Jr.! Who better than "Iron Man" to talk about the technological wonders that will radically change our lives in the coming years? Robert himself is, inter alia, the co-financier of Footprint Coalition, a private organization created with the aim of cleaning up our planet through robotics and cutting-edge technologies.Many sessions were organized by disruptive companies that presented innovations made possible by artificial intelligence: oil & gas companies, private space companies for the launch of artificial satellites and, above all, the incredible Amazon GO, the chain of Amazon stores where it is possible to do shopping and checkout without going through the cash registers. As the motto says, "no lines, no checkout. NO seriously! ": Thanks to machine learning techniques and simulations in 3D environments, anyone who enters a store is labeled at the entrance, so as to keep track of the actions and items taken from the shelves: upon exiting the store, the system of Amazon GO processes the "cart" and sends the invoice directly to the user's personal Amazon profile. An incredible experience!While the official sessions only started on June 5th, right from the first day it was possible to participate in workshops on some specific topics; we immediately identified one that particularly excited our nerd fantasies: a deep-dive on AWS DeepRacer!The workshop really impressed us: introduced by the keynote speaker of re:Invent 2018 by Andy Jassy, this 4WD model with monster truck axle is able to learn how to move autonomously on predetermined paths through Reinforcement Learning. Described by AWS as the easiest way to learn Machine Learning, AWS DeepRacer keeps all it promises. The series of steps to get on track and watch your car run is truly minimal. It is possible to have a model trained for driving in just under an hour, although, obviously, more experiments and much more time are needed to get good results.We immediately experimented with as many options as possible to improve our time on the track from time to time. Among other things, the re:MARS is one of the stops of the DeepRacer League, a competition that takes place in conjunction with the main AWS events.What better opportunity to learn directly in the field?
In the last few years, Las Vegas has become the reference point for AWS Cloud events. We have seen first-hand re:Invent grow from 6,000 participants in 2012 to over 40,000 last year. An immense event, in which it has become difficult to simply choose the sessions in which to participate! It must also be for this reason that this year, AWS has decided to complement their main event with some conferences with a more specific focus, the first of which, the AWS Re:MARS, was created around the hottest topics of the moment: Machine Learning, Automation, Robotics and Space.beSharp - obviously - could not miss it.Many big names were present as keynote speakers: Jeff Bezos, Werner Vogels, Coursera co-founder Andrew Ng, IRobot CEO and founder Colin M. Angle and ... Robert Downey Jr.! Who better than "Iron Man" to talk about the technological wonders that will radically change our lives in the coming years? Robert himself is, inter alia, the co-financier of Footprint Coalition, a private organization created with the aim of cleaning up our planet through robotics and cutting-edge technologies.Many sessions were organized by disruptive companies that presented innovations made possible by artificial intelligence: oil & gas companies, private space companies for the launch of artificial satellites and, above all, the incredible Amazon GO, the chain of Amazon stores where it is possible to do shopping and checkout without going through the cash registers. As the motto says, "no lines, no checkout. NO seriously! ": Thanks to machine learning techniques and simulations in 3D environments, anyone who enters a store is labeled at the entrance, so as to keep track of the actions and items taken from the shelves: upon exiting the store, the system of Amazon GO processes the "cart" and sends the invoice directly to the user's personal Amazon profile. An incredible experience!While the official sessions only started on June 5th, right from the first day it was possible to participate in workshops on some specific topics; we immediately identified one that particularly excited our nerd fantasies: a deep-dive on AWS DeepRacer!The workshop really impressed us: introduced by the keynote speaker of re:Invent 2018 by Andy Jassy, this 4WD model with monster truck axle is able to learn how to move autonomously on predetermined paths through Reinforcement Learning. Described by AWS as the easiest way to learn Machine Learning, AWS DeepRacer keeps all it promises. The series of steps to get on track and watch your car run is truly minimal. It is possible to have a model trained for driving in just under an hour, although, obviously, more experiments and much more time are needed to get good results.We immediately experimented with as many options as possible to improve our time on the track from time to time. Among other things, the re:MARS is one of the stops of the DeepRacer League, a competition that takes place in conjunction with the main AWS events.What better opportunity to learn directly in the field? From the home screen, you can see our models, check the status of the training and create new ones.
From the home screen, you can see our models, check the status of the training and create new ones. To begin, let’s create a new model by clicking on "Create model".This screen presents the features of the model, as well as checking if we have all the permissions on the account to be able to save it correctly.
To begin, let’s create a new model by clicking on "Create model".This screen presents the features of the model, as well as checking if we have all the permissions on the account to be able to save it correctly. In case there is anything to fix, AWS will notify you and help you correct it.We enter a name and a description: choose a name that is easy to remember and above all unique because, if you want to compete in an official race, you will be asked to transfer your model to the scale race car through a USB key, and then to identify it from those loaded through an app from the track marshal iPad.We choose a track to drive the model: we have selected the first, which is the official circuit for the DeepRacer League, "re:Invent 2018". You can try any available track.
In case there is anything to fix, AWS will notify you and help you correct it.We enter a name and a description: choose a name that is easy to remember and above all unique because, if you want to compete in an official race, you will be asked to transfer your model to the scale race car through a USB key, and then to identify it from those loaded through an app from the track marshal iPad.We choose a track to drive the model: we have selected the first, which is the official circuit for the DeepRacer League, "re:Invent 2018". You can try any available track.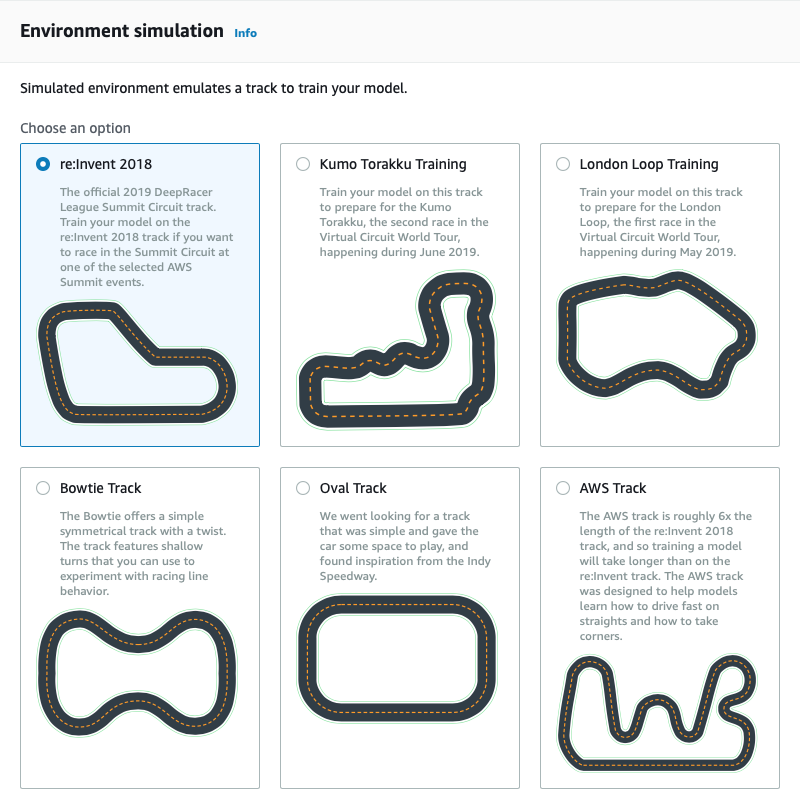 Once the training track has been selected, it is time to create the reward function with which we will train the model. This step is essential to obtain a performing car and get good scores in the races.Before telling you about our experience, it is useful to briefly reiterate how Reinforcement Learning works.Reinforcement Learning is a training system of unsupervised neural networks, neural networks that do not need an initial ground truth with which to adapt their own weights. Indeed, Reinforcement Learning performs different measurements of the surrounding environment to maximize its reward function. During this process, which is repeated indefinitely until a cutoff threshold is reached, the weights of the network are updated each time, thus optimizing the network itself.In the case of the DeepRacer Car, we started with a very simple reward function, whose goal is to teach the car to stay in the middle of the track; this means returning a higher reward value if, at the time of measurement, the distance from the center of the roadway is less than half the width of the road. In all other cases, the reward is reduced.Below is an example of how to construct the function:
Once the training track has been selected, it is time to create the reward function with which we will train the model. This step is essential to obtain a performing car and get good scores in the races.Before telling you about our experience, it is useful to briefly reiterate how Reinforcement Learning works.Reinforcement Learning is a training system of unsupervised neural networks, neural networks that do not need an initial ground truth with which to adapt their own weights. Indeed, Reinforcement Learning performs different measurements of the surrounding environment to maximize its reward function. During this process, which is repeated indefinitely until a cutoff threshold is reached, the weights of the network are updated each time, thus optimizing the network itself.In the case of the DeepRacer Car, we started with a very simple reward function, whose goal is to teach the car to stay in the middle of the track; this means returning a higher reward value if, at the time of measurement, the distance from the center of the roadway is less than half the width of the road. In all other cases, the reward is reduced.Below is an example of how to construct the function:import math def reward_function(params): ''' Use square root for center line ''' track_width = params['track_width'] distance_from_center = params['distance_from_center'] reward = 1 - math.sqrt(distance_from_center / (track_width/2)) if reward < 0: reward = 0 return float(reward)We choose the degrees of freedom of our 4WD: maximum speed, steering angle and possible speed levels. The linear combination of this information defines how many variations the car is able to manage both in the case of steering and speed changes.
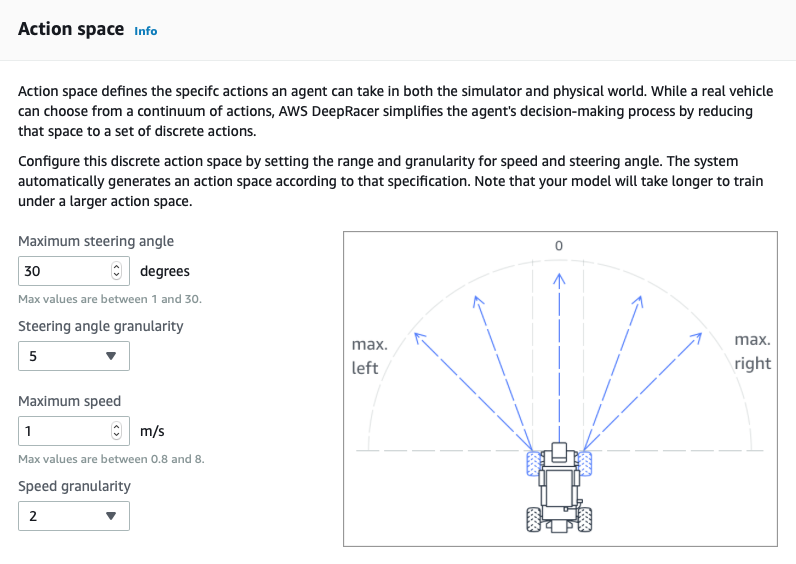 This operation is strongly dependent on the training function and vice versa: often, alterations in the degrees of freedom on the reward function produce very different results between them.
This operation is strongly dependent on the training function and vice versa: often, alterations in the degrees of freedom on the reward function produce very different results between them.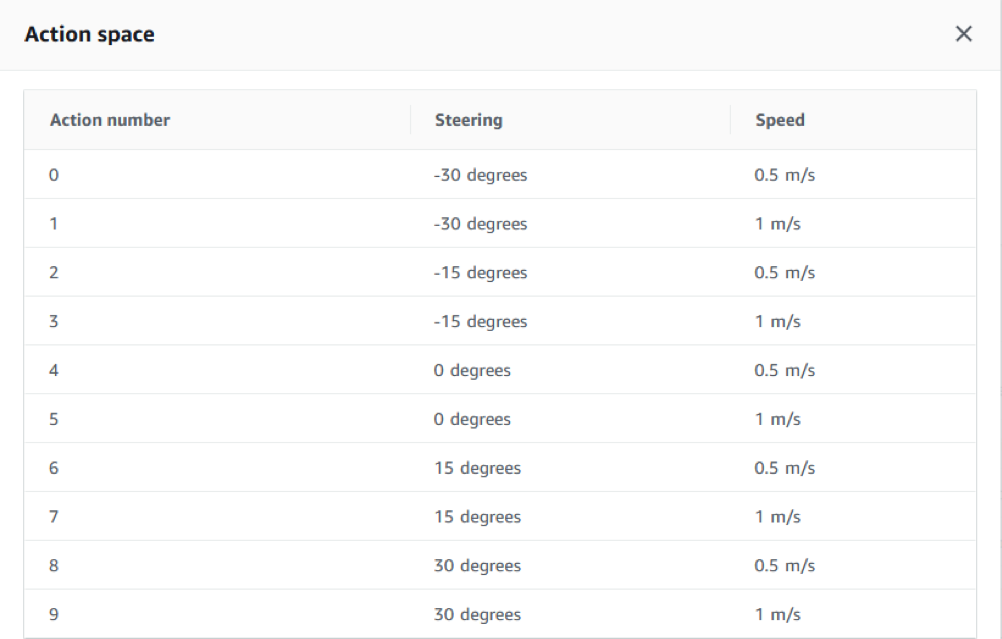 Enter this information; you can decide how many hours to train the model, up to a maximum of 8 hours per single operation.It is useful to know that it is possible to further re-train the same model to increase the degree of confidence. What we have verified is that, with a training time of around 8 - 10 hours, it is possible to give the car a certain confidence on the track, provided you keep a simple model.We perform some confidence tests on the function described above: from the main screen of the model, we click on "Start new evaluation" and choose the number of "trials" on the track; with three tests, the results are the following:
Enter this information; you can decide how many hours to train the model, up to a maximum of 8 hours per single operation.It is useful to know that it is possible to further re-train the same model to increase the degree of confidence. What we have verified is that, with a training time of around 8 - 10 hours, it is possible to give the car a certain confidence on the track, provided you keep a simple model.We perform some confidence tests on the function described above: from the main screen of the model, we click on "Start new evaluation" and choose the number of "trials" on the track; with three tests, the results are the following: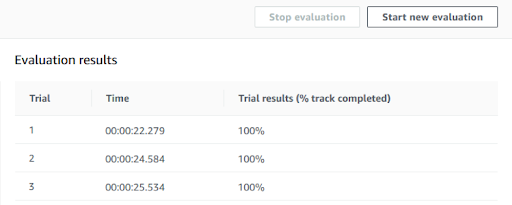 Not bad as a first result, but we certainly could not stop at 23 seconds! Therefore, here are the different variables that DeepRacer provides to manipulate its reward function
Not bad as a first result, but we certainly could not stop at 23 seconds! Therefore, here are the different variables that DeepRacer provides to manipulate its reward function{ "all_wheels_on_track": Boolean, # flag to indicate if the vehicle is on the track "x": float, # vehicle's x-coordinate in meters "y": float, # vehicle's y-coordinate in meters "distance_from_center": float, # distance in meters from the track center "is_left_of_center": Boolean, # Flag to indicate if the vehicle is on the left side to the track center or not. "heading": float, # vehicle's yaw in degrees "progress": float, # percentage of track completed "steps": int, # number steps completed "speed": float, # vehicle's speed in meters per second (m/s) "steering_angle": float, # vehicle's steering angle in degrees "track_width": float, # width of the track "waypoints": [[float, float], … ], # list of [x,y] as milestones along the track center "closest_waypoints": [int, int] # indices of the two nearest waypoints. }Let’s try to add some of this information to our reward function:
import math def reward_function(params): ''' Use square root for center line ''' track_width = params['track_width'] distance_from_center = params['distance_from_center'] steering = abs(params['steering_angle']) speed = params['speed'] all_wheels_on_track = params['all_wheels_on_track'] ABS_STEERING_THRESHOLD = 15 reward = 1 - (distance_from_center / (track_width/2))**(4) if reward < 0: reward = 0 if steering > ABS_STEERING_THRESHOLD: reward *= 0.8 if not (all_wheels_on_track): reward = 0 return float(reward)In particular, we added the "steering angle", the "speed" and the Boolean variable "all_wheels_on_track", which shows us if at a given moment the car has all the wheels off the track.If we look at the code, we see that the reward function, after being calculated with respect to the position relative to the center of the track, is modified as follows:
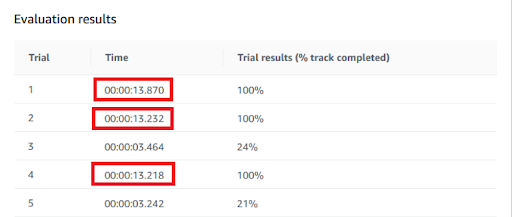 We note how the model has not always completed the circuit, but the times in which it has succeeded, it has shown a remarkable improvement of the times on the track, bringing the average from 22 to little over 13 seconds.We took part in the first day of the competition with this model.
We note how the model has not always completed the circuit, but the times in which it has succeeded, it has shown a remarkable improvement of the times on the track, bringing the average from 22 to little over 13 seconds.We took part in the first day of the competition with this model. From the list of trained models, select the model to download and press, "Download model". The model is downloaded in compressed format and must be copied to the USB stick in a directory called "Models".
From the list of trained models, select the model to download and press, "Download model". The model is downloaded in compressed format and must be copied to the USB stick in a directory called "Models".Once this is done, we are ready to compete! We await our turn by observing the performance of our opponents: some set excellent times; others go off the road all the time. A few curious people just try to race with the AWS sample models.
 It is our turn: we fill out our profile and register for the next race. We choose "beSharp" and "beSharp-2" as the name of our cars: now we have to make a good impression!The USB key with the model is loaded into the DeepRacer Car, and an operator synchronizes everything on the iPad that is used by the "pilot" to control the behavior of the machine.On the iPad, we have three commands available:
It is our turn: we fill out our profile and register for the next race. We choose "beSharp" and "beSharp-2" as the name of our cars: now we have to make a good impression!The USB key with the model is loaded into the DeepRacer Car, and an operator synchronizes everything on the iPad that is used by the "pilot" to control the behavior of the machine.On the iPad, we have three commands available:import math def reward_function(params): ''' Use square root for center line ''' track_width = params['track_width'] distance_from_center = params['distance_from_center'] speed = params['speed'] progress = params['progress'] all_wheels_on_track = params['all_wheels_on_track'] SPEED_TRESHOLD = 6 reward = 1 - (distance_from_center / (track_width/2))**(4) if reward < 0: reward = 0 if speed > SPEED_TRESHOLD: reward *= 0.8 if not (all_wheels_on_track): reward = 0 if progress == 100: reward += 100 return float(reward)In this new function, we are going to reduce the reward if the machine speed decreases and we give a much higher score if the machine manages to complete the track.
import math def reward_function(params): track_width = params['track_width'] distance_from_center = params['distance_from_center'] steering = abs(params['steering_angle']) direction_stearing=params['steering_angle'] speed = params['speed'] steps = params['steps'] progress = params['progress'] all_wheels_on_track = params['all_wheels_on_track'] ABS_STEERING_THRESHOLD = 15 SPEED_TRESHOLD = 5 TOTAL_NUM_STEPS = 85 # Read input variables waypoints = params['waypoints'] closest_waypoints = params['closest_waypoints'] heading = params['heading'] reward = 1.0 if progress == 100: reward += 100 # Calculate the direction of the center line based on the closest waypoints next_point = waypoints[closest_waypoints[1]] prev_point = waypoints[closest_waypoints[0]] # Calculate the direction in radius, arctan2(dy, dx), the result is (-pi, pi) in radians track_direction = math.atan2(next_point[1] - prev_point[1], next_point[0] - prev_point[0]) # Convert to degree track_direction = math.degrees(track_direction) # Calculate the difference between the track direction and the heading direction of the car direction_diff = abs(track_direction - heading) # Penalize the reward if the difference is too large DIRECTION_THRESHOLD = 10.0 malus=1 if direction_diff > DIRECTION_THRESHOLD: malus=1-(direction_diff/50) if malus<0 or malus>1: malus = 0 reward *= malus return rewardWe get to the track on the morning of the last day, skipping lunch (for the glory, this and more!) We start to run: the algorithm seems to work well at high speeds, but the overall stability is not the best. After the first uncertain laps, we understand how to regulate ourselves with speed: the penultimate perfect lap, the commentator shouts: 10 seconds and 272 thousandths! We are in the Top Ten again, but there are several hours left to the end of the race and our tenth position is shaky.Second run, now we know how to manually manage the speed of the car in the various points of the track and we can meet our model to make the most of it.After a few attempts, we only have time for a final lap: 9,222 seconds, eighth place four hours from the end.Let us go back to following the sessions with an eye on the real-time ranking, some new competitors at the bottom of the list and the usual five competing for the top positions. It was not until Thursday that the world record on the track was broken twice, falling below 7.7 seconds!Our time holds up! We win an honorable eighth place and a DeepRacer Car!
 What did we take home from this experience? If the main purpose of DeepRacer is to teach Machine Learning in an easy and fun way, mission accomplished! Among spin offs, twists, and overtakes in standing we had the opportunity to study and test some simple but effective Reinforcement Learning notions.Hoping that there will soon be new opportunities to get on track, we want to share some of our notes with you:
What did we take home from this experience? If the main purpose of DeepRacer is to teach Machine Learning in an easy and fun way, mission accomplished! Among spin offs, twists, and overtakes in standing we had the opportunity to study and test some simple but effective Reinforcement Learning notions.Hoping that there will soon be new opportunities to get on track, we want to share some of our notes with you:


