
Telemetria Enterprise su AWS: Gestire backfill di dati massivi con ECS e Databricks senza far esp...
17 Giugno 2026 - 2 min. read
Keidi Xhafa



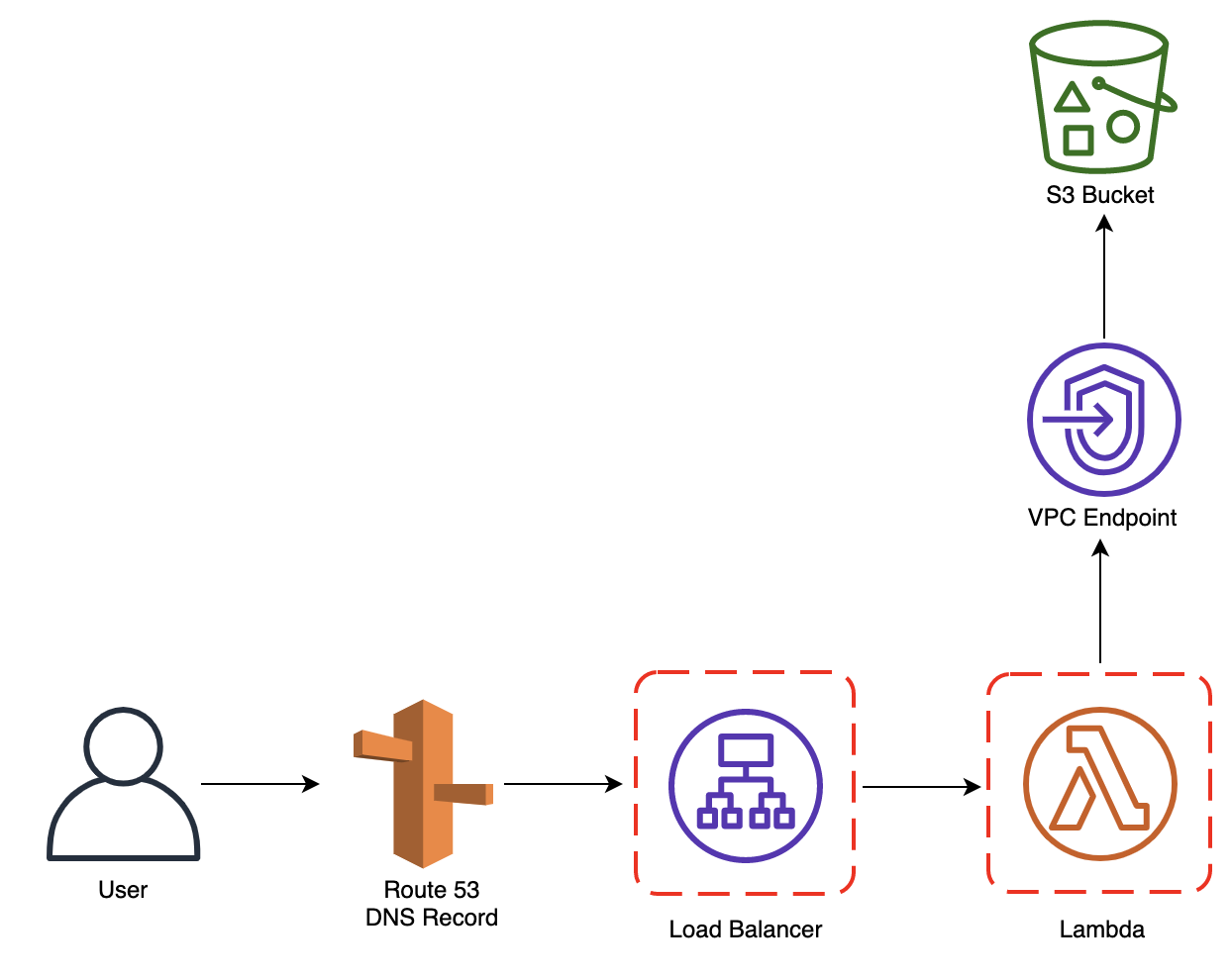
S3Bucket:
Type: AWS::S3::Bucket
Properties:
BucketName: 'subdomain.mydomain.com'
CorsConfiguration:
CorsRules:
- AllowedHeaders:
- '*'
AllowedMethods:
- GET
- HEAD
- POST
- PUT
- DELETE
AllowedOrigins:
- 'https://*.mydomain.com'
PublicAccessBlockConfiguration:
BlockPublicAcls: true
BlockPublicPolicy: true
IgnorePublicAcls: true
RestrictPublicBuckets: true
WebsiteConfiguration:
ErrorDocument: error.html
IndexDocument: index.html
S3BucketPolicy:
Type: AWS::S3::BucketPolicy
Properties:
Bucket: !Ref S3Bucket
PolicyDocument:
Version: '2012-10-17'
Statement:
- Sid: VPCEndpointReadGetObject
Effect: Allow
Principal: "*"
Action: s3:GetObject
Resource: !Sub '${S3Bucket.Arn}/*'
Condition:
StringEquals:
aws:sourceVpce: !Ref S3VPCEndpointId
Come si può notare, è stata attivata la “website configuration” in modo tale da poterci interfacciare con il bucket tramite chiamate HTTP ma allo stesso tempo è presente anche una Bucket Policy che vieta il recupero di un qualsiasi oggetto a meno che la richiesta non passi dal VPC Endpoint di S3, garantendo quindi che solo gli interlocutori che passano dalla VPC dell’account possano accedere al Bucket stesso. LoadBalancer:
Type: AWS::ElasticLoadBalancingV2::LoadBalancer
Properties:
Name: !Sub '${ProjectName}'
LoadBalancerAttributes:
- Key: 'idle_timeout.timeout_seconds'
Value: '60'
- Key: 'routing.http2.enabled'
Value: 'true'
- Key: 'access_logs.s3.enabled'
Value: 'true'
- Key: 'access_logs.s3.prefix'
Value: loadbalancers
- Key: 'access_logs.s3.bucket'
Value: !Ref S3LogsBucketName
Scheme: internet-facing
SecurityGroups:
- !Ref LoadBalancerSecurityGroup
Subnets:
- !Ref SubnetPublicAId
- !Ref SubnetPublicBId
- !Ref SubnetPublicCId
Type: application
LoadBalancerSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupName: !Sub '${ProjectName}-alb'
GroupDescription: !Sub '${ProjectName} Load Balancer Security Group'
SecurityGroupIngress:
- CidrIp: 0.0.0.0/0
Description: ALB Ingress rule from world
FromPort: 80
ToPort: 80
IpProtocol: tcp
- CidrIp: 0.0.0.0/0
Description: ALB Ingress rule from world
FromPort: 443
ToPort: 443
IpProtocol: tcp
Tags:
- Key: Name
Value: !Sub '${ProjectName}-alb'
- Key: Environment
Value: !Ref Environment
VpcId: !Ref VPCId
HttpListener:
Type: AWS::ElasticLoadBalancingV2::Listener
Properties:
DefaultActions:
- RedirectConfig:
Port: '443'
Protocol: HTTPS
StatusCode: 'HTTP_301'
Type: redirect
LoadBalancerArn: !Ref LoadBalancer
Port: 80
Protocol: HTTP
HttpsListener:
Type: AWS::ElasticLoadBalancingV2::Listener
Properties:
Certificates:
- CertificateArn: !Ref LoadBalancerCertificateArn
DefaultActions:
- Type: forward
TargetGroupArn: !Ref TargetGroup
LoadBalancerArn: !Ref LoadBalancer
Port: 443
Protocol: HTTPS
TargetGroup:
Type: AWS::ElasticLoadBalancingV2::TargetGroup
Properties:
Name: !Sub '${ProjectName}'
HealthCheckEnabled: false
TargetType: lambda
Targets:
- Id: !GetAtt Lambda.Arn
DependsOn: LambdaPermission
Tramite questo template, viene deployato un Load Balancer pubblico con un listener che ascolta sulla porta 80 (HTTP) che effettua una redirect su 443 (HTTPS) su cui è presente un altro listener che però contatta un Target Group su cui è registrata una Lambda.import json
from boto3 import client as boto3_client
from os import environ as os_environ
import base64
from urllib3 import PoolManager
http = PoolManager()
s3 = boto3_client('s3')
def handler(event, context):
try:
print(event)
print(context)
host = event['headers']['host']
print("Host:", host)
feature = host.split('.')[0]
feature = "-".join(feature.split('-')[1:])
print("Feature:", feature)
path = event['path'] if event['path'] != "/" else "/index.html"
print("Path:", path)
query_string_parameters = event['queryStringParameters']
query_string_parameters = [f"{key}={value}" for key, value in event['queryStringParameters'].items()]
print("Query String Parameters:", query_string_parameters)
http_method = event["httpMethod"]
url = f"http://{os_environ['S3_BUCKET']}.s3-website-eu-west-1.amazonaws.com/{feature}{path}{'?' if [] != query_string_parameters else ''}{'&'.join(query_string_parameters)}"
print(url)
headers = event['headers']
headers.pop("host")
print("Headers:", headers)
body = event['body']
print("Body:", body)
r = http.request(http_method, url, headers=headers, body=body)
print("Response:", r)
print("Response Data:", r.data)
try:
decoded_response = base64.b64encode(r.data).decode('utf-8')
except:
decoded_response = base64.b64encode(r.data)
print("Decoded Response:", decoded_response)
print("Headers Response:", dict(r.headers))
return {
'statusCode': 200,
'body': decoded_response,
"headers": dict(r.headers),
"isBase64Encoded": True
}
except Exception as e:
print(e)
return {
'statusCode': 400
}
Nonostante non sia di immediata lettura, le operazioni effettuate sono molto semplici: partendo dal DNS name con cui l’utente ha raggiunto il Load Balancer, la Lambda gira la chiamata verso il Bucket S3 costruendo la sottocartella da contattare contenente una determinata feature. Per far si che tutto ciò funzioni bisogna chiaramente creare un DNS name per ciascuna feature.

