
Quando il Serverless “gira” sui server: nuove opzioni per AWS Lambda e AWS Fargate co...
04 Marzo 2026 - 14 min. read
Damiano Giorgi
DevOps Engineer



Ormai non è più una citazione, ma un mantra:
“Everything fails, all the time” - Werner Vogels
Questo principio ha condizionato la metodologia con cui si progetta infrastrutture in Cloud. Bisogna valutare le diverse tipologie di fallimento prima di progettare. Non tutti i disastri, però, sono uguali. Proviamo a darne una classificazione:
Per rispondere in maniera efficace a queste tre tipologie di disastro bisogna progettare e pianificare in tre maniere diverse:
In questa serie di articoli ci concentreremo in particolare sul Disaster Recovery, dalla sua definizione, fino alle tecniche di ripristino e come l’ecosistema di servizi AWS ci può aiutare a garantire la continuità del business in qualunque situazione.
Il Disaster Recovery (DR) è un processo fondamentale per garantire la continuità delle operazioni aziendali in caso di disastri informatici. Esistono diverse tecniche di DR, e tutte mirano a ripristinare le applicazioni, i dati e le infrastrutture IT il più rapidamente possibile dopo un evento avverso.
In ambito Cloud, il DR è ancora più importante, poiché le applicazioni e i dati sono ospitati in remoto su server e infrastrutture che possono essere soggette a interruzioni di servizio a causa di problemi di connettività, guasti hardware, attacchi informatici o disastri naturali.
Ogni volta che si affronta questo argomento e per garantire un DR efficace è necessario partire da due acronimi che sono fondamentali per la selezione della miglior strategia di DR:
RTO (Recovery Time Objective), in questo caso la domanda a cui dobbiamo rispondere è: per quanto tempo possiamo lasciare i nostri sistemi non funzionanti prima di tornare operativi?
Il concetto di RTO si riferisce quindi al tempo che intercorre tra il disastro e il completo ripristino dei sistemi.

In sintesi, il DR è un processo fondamentale per garantire la continuità delle operazioni aziendali in caso di disastri informatici, e la sua efficacia dipende dall'obiettivo RTO/RPO e dal giusto equilibrio tra consistenza, disponibilità e tolleranza ai guasti.
Esistono diversi approcci per il Disaster Recovery, e la scelta dipende da fattori come il budget, la criticità dei dati e delle applicazioni, il tempo di ripristino accettabile (RTO) e il punto di ripristino accettabile (RPO).
Tra i metodi più comuni per il DR troviamo:
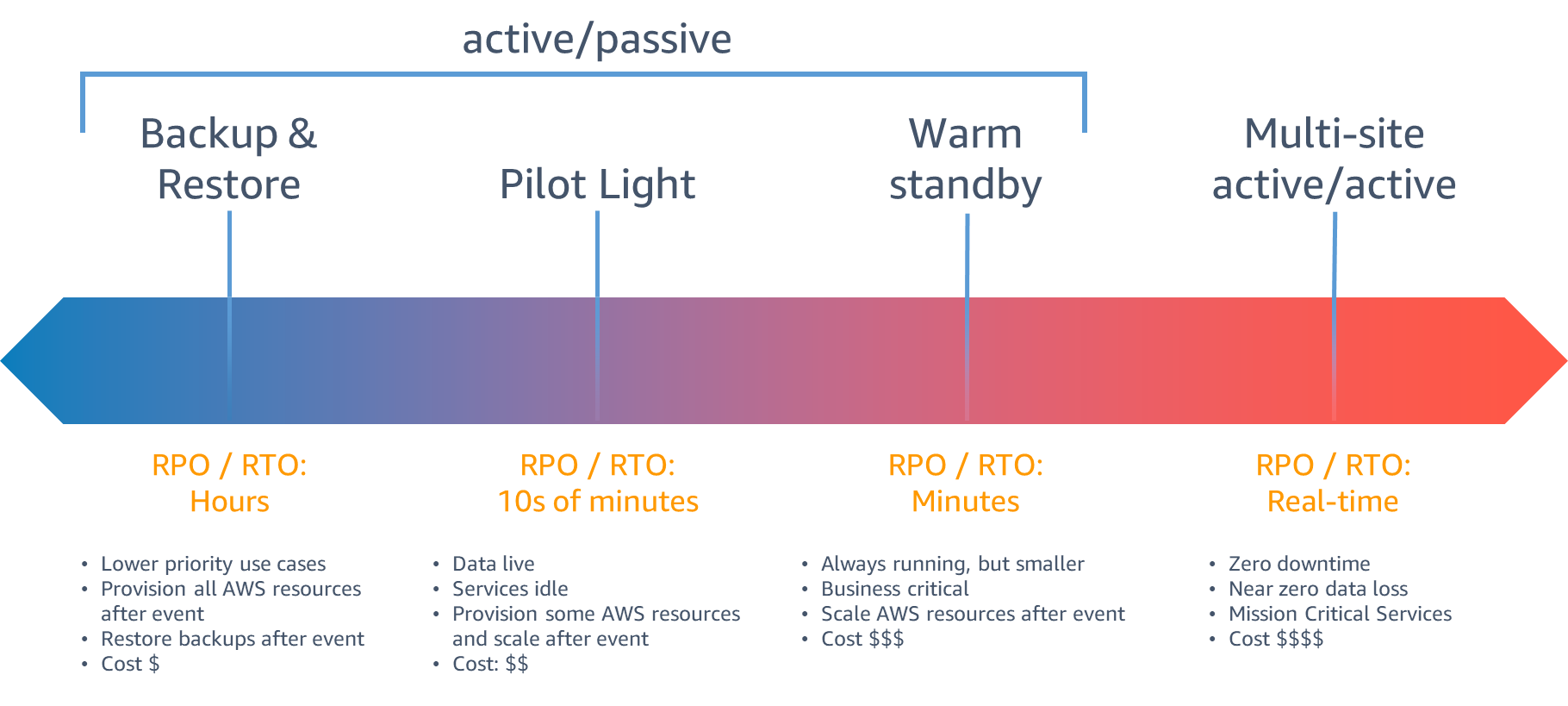
Per quanto riguarda l'applicazione delle tecniche di DR in realtà di diverse dimensioni, possiamo dire che ogni organizzazione deve scegliere il metodo più adatto alle proprie esigenze e risorse. Le aziende di grandi dimensioni spesso hanno budget più elevati e possono permettersi di investire in infrastrutture costose come repliche attive e in costante sincronizzazione.
Le piccole e medie imprese, invece, possono optare per soluzioni più economiche e flessibili, come la replica dei dati nel cloud.
In sintesi, la scelta del metodo di Disaster Recovery dipende dalle esigenze dell'organizzazione, dal budget e dalla criticità dei dati e delle applicazioni.
Fin qui sembra tutto chiaro e lineare. Durante la replica dei dati per il disaster recovery, però, ci sono diversi fattori tecnici che devono essere presi in considerazione e che possono condizionare RPO/RTO. Tra i principali si annoverano:
Ovviamente la coperta è sempre troppo corta e dobbiamo essere consapevoli che il disaster recovery deve necessariamente essere un compromesso. A sostegno di questo vorrei riportare un teorema fondamentale per i sistemi distribuiti: il CAP theorem.
Il teorema CAP (Consistency, Availability, Partition tolerance), che riguarda normalmente i sistemi di database distribuiti, può essere applicato in modo analogo al contesto del Disaster Recovery (DR), sebbene con alcune considerazioni aggiuntive. Noto anche come teorema di Brewer, afferma che è impossibile per un sistema informatico distribuito fornire simultaneamente tutte e tre le seguenti garanzie:
Quando si applica il teorema CAP al DR, spesso si fa una scelta consapevole per bilanciare la coerenza, la disponibilità e la tolleranza alla partizione in base alle esigenze specifiche del business e alle conseguenze delle interruzioni. Ad esempio, in un ambiente di ripristino prioritario, si potrebbe dare priorità alla disponibilità, sacrificando temporaneamente la coerenza dei dati. Al contrario, in un ambiente altamente sensibile alla coerenza, si potrebbe priorizzare la coerenza sacrificando temporaneamente la disponibilità.
Tutto questo solo per capire come si fa disaster recovery, come si passa da produzione al nostro sito secondario. Ma c’è un punto della questione che è essenziale e che viene trascurato sempre da tutti, ovvero progettare come si torna in produzione dopo che l’evento disastroso è rientrato. Insomma, ci si dimentica sempre di definire come si “torna indietro”.
Anche in questo caso è importante seguire un processo ben pianificato per garantire una transizione sicura e senza intoppi.
Prima di tutto bisogna fare una valutazione del ripristino. Prima di tornare alla produzione normale, è necessario valutare attentamente lo stato del sistema e dell'ambiente di produzione. Verificare che il problema o l'evento di interruzione sia stato risolto completamente e che l'ambiente sia pronto per il ripristino. In questo caso è fondamentale avere dei buoni sistemi di monitoring per rilevare eventuali anomalie o problemi. L’utilizzo di strumenti di monitoraggio e avvisi è utile per identificare e risolvere tempestivamente qualsiasi problema che possa verificarsi durante la transizione al ritorno in produzione. Repetita iuvant: il monitoring è fondamentale anche post-ripristino per consentirci di individuare eventuali problemi residui o effetti collaterali che potrebbero emergere e intervenire tempestivamente per risolverli.
Non basta che l’ambiente di produzione sia finalmente disponibile, ma vanno eseguiti test e convalide. Ciò può includere test funzionali, test di carico e altri test appropriati per garantire che tutto funzioni correttamente come previsto. Verificare che i dati siano coerenti e integri.
In alcuni casi, potrebbe essere necessario eseguire un rollback delle modifiche apportate durante il processo di DR. Questo può coinvolgere il ripristino delle configurazioni, delle modifiche applicative o delle versioni precedenti dei dati. È importante pianificare il rollback in modo da minimizzare l'impatto sulle operazioni e garantire la coerenza dei dati.
Da non sottovalutare nelle situazioni emergenziali è la comunicazione con gli utenti e gli stakeholder coinvolti. Le persone coinvolte devono essere rese consapevoli delle modifiche apportate e dei passaggi necessari per tornare alla produzione normale.
Per rendere edotte le persone coinvolte è necessario documentare le nostre procedure, ovvero registrare tutti i passaggi, le modifiche apportate e le azioni intraprese durante il processo di DR. Ciò aiuterà a ricostruire l'evento di interruzione e ad analizzare in seguito per migliorare le future strategie di DR.
Siamo giunti al termine della prima tappa del nostro viaggio nel Disaster Recovery in Cloud. Dopo averne definito i macro concetti e averne compreso la dinamiche, è il momento di entrare nel vivo dell’implementazione delle tecniche di DR in scenari aziendali complessi.
Cominceremo approfondendo nel prossimo articolo le migliori tecniche di DR per i contesti di tipo ibrido on-prem to Cloud per poi parlare di DR per la Business Continuity in ambito Cloud-to-Cloud nel terzo articolo della nostra mini-serie.
Pronti?
Ci vediamo tra 14 giorni su Proud2beCloud!
Proud2beCloud è il blog di beSharp, APN Premier Consulting Partner italiano esperto nella progettazione, implementazione e gestione di infrastrutture Cloud complesse e servizi AWS avanzati. Prima di essere scrittori, siamo Solutions Architect che, dal 2007, lavorano quotidianamente con i servizi AWS. Siamo innovatori alla costante ricerca della soluzione più all'avanguardia per noi e per i nostri clienti. Su Proud2beCloud condividiamo regolarmente i nostri migliori spunti con chi come noi, per lavoro o per passione, lavora con il Cloud di AWS. Partecipa alla discussione!

