
Architetture Event-Driven a KM0: dal producer al consumer – Parte 2
11 Febbraio 2026 - 13 min. read
Eric Villa
Solutions Architect


Oggigiorno è sempre più importante poter monitorare e tracciare lo stato delle proprie applicazione, come saper identificare facilmente la fonte di problematiche. Contando il numero sempre più crescente di servizi digitali, indipendentemente dalla loro grandezza e importantanza, questa esigenza è sempre più sentita.
Ad oggi ci si scontra anche con molti pattern infrastrutturali moderni e sempre più complessi, pensiamo al mondo microservizi o serverless. Bisogna trovare strumenti efficaci e centralizzati per il monitoraggio.
Lungi da noi andare a descrivere e comparare i vari programmi di logging management, non basterebbe un solo articolo! Possiamo dire, però, che sul mondo AWS questi problemi vengono notevolmente ridotti grazie alle numerose alternative che abbiamo a disposizione, unitamente al vantaggio dei servizi totalmente gestiti!
In questo articolo andremo a parlare di come centralizzare e gestire in modo efficiente i log provenienti da varie applicazioni, restando interamente sul mondo AWS! Nello specifico, esploreremo un’alternativa alla popolare soluzione di log aggregation, lo stack ELK (Elasticsearch, Logstash, Kibana), ovvero lo stack EKK (Amazon Elasticsearch Service, Amazon Kinesis e Kibana).
Iniziamo con una breve descrizione dello stack ELK. Per chi di voi lo conoscesse, facciamo un ripasso insieme! Come per la storia, anche nell’informatica risulta utile conoscere il passato per comprendere a meglio il presente.
Partendo dal diagramma riportato sotto, lo stack ELK è composto dai seguenti componenti:
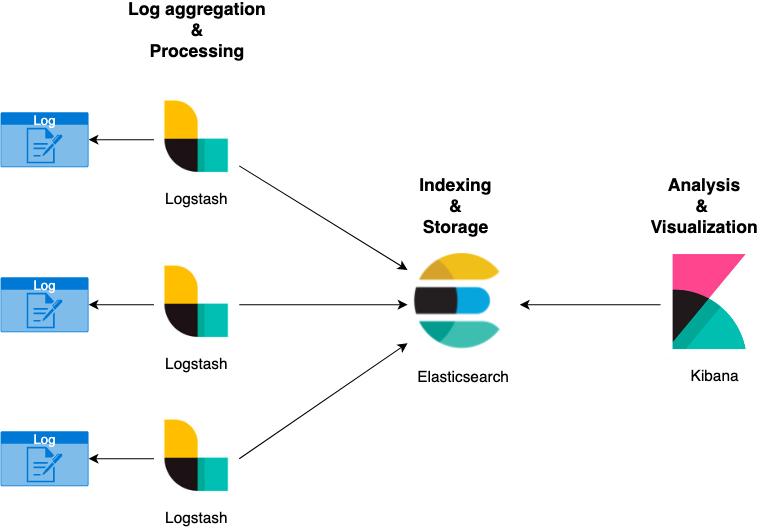
Presentato così, potrebbe risultare relativamente complessa la semplice funzione di “logging” della nostra applicazione. Tuttavia, questo stack ad oggi è utilizzato moltissimo per la sua versatilità e la sua scalabilità.
Ma non è di questa struttura che andremo a parlare, bensì di un suo “fork” cloud-native sul mondo AWS! Tratteremo infatti lo stack EKK, i componenti che entrano in gioco diventano:
Il diagramma infrastrutturale si trasforma come di seguito:
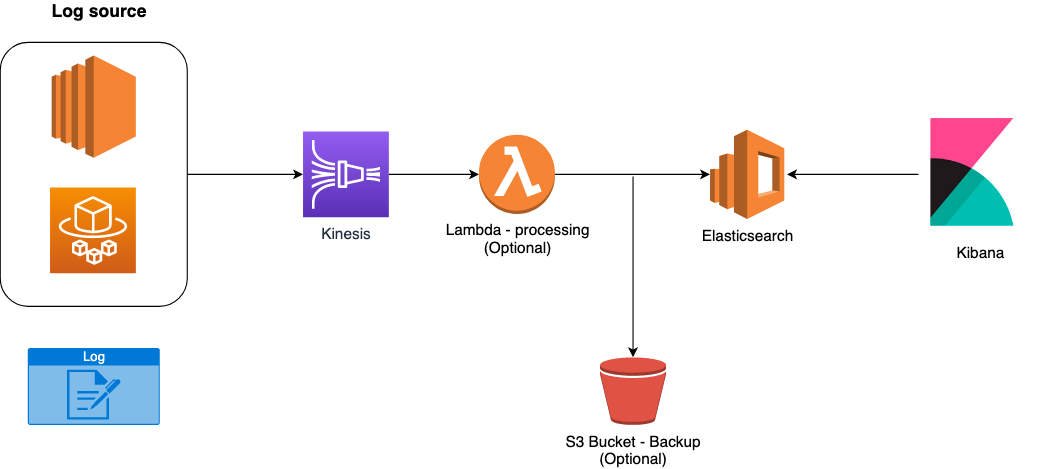
Comodo, vero? Dimentichiamoci il provisioning e la gestione di macchine EC2, oltre al loro scaling, manutenzione e configurazione in alta disponibilità. Questi servizi, totalmente gestiti da AWS, vengono in nostro soccorso permettendoci di concentrarci sulla nostra applicazione e ridurre attività costose, in termini di tempo, per la “banale” infrastruttura legata all’aggregazione e presentazione dei log.
Per i più diffidenti, il dover mandare i dati a Firehose potrebbe non risultare la scelta migliore. Ma vediamo di illustrarne i vantaggi.
Innanzitutto, esiste un’integrazione nativa tra Kinesis e Elasticsearch gestito da AWS! Inoltre, possiamo decidere di effettuare attività di processing su tutti i dati in ingresso, se fosse ad esempio necessario formattare i log in arrivo da tutti i sistemi sorgenti.
Non basta? Su Kinesis possiamo anche selezionare un bucket S3 per salvare i log, così facendo saranno disponibili in futuro per eventuali analisi o spostamento su altre piattaforme.
Per ridurre i costi, nulla ci vieta di spostare i dati su altri S3 Tier più economici rispetto a quello Standard.
Tra le funzioni offerta da Kinesis, c’è poi quella di batching, encryption e retry per gestire al meglio le richieste verso il server di Elasticsearch.
Ma quali sorgenti possiamo utilizzare con Kinesis? Idealmente, qualsiasi! E’ infatti possibile richiamare direttamente le API (ad esempio quelle fornite dai vari SDK), oppure possiamo utilizzare strumenti già forniti da AWS se stiamo utilizzando i suoi servizi di computing più noti.
Facciamo qualche esempio:
Riassumendo, abbiamo visto come riportare il classico stack ELK in ottica cloud-native AWS, trasformandolo quindi in stack EKK per sfruttare i vantaggi dei servizi gestiti da AWS.
Non vedete l’ora di fare un po’ di pratica? Perfetto! Facciamo una breve demo utilizzando un cluster ECS in modalità Fargate!
Prima di partire con la demo, elenchiamo i servizi che andremo ad utilizzare:
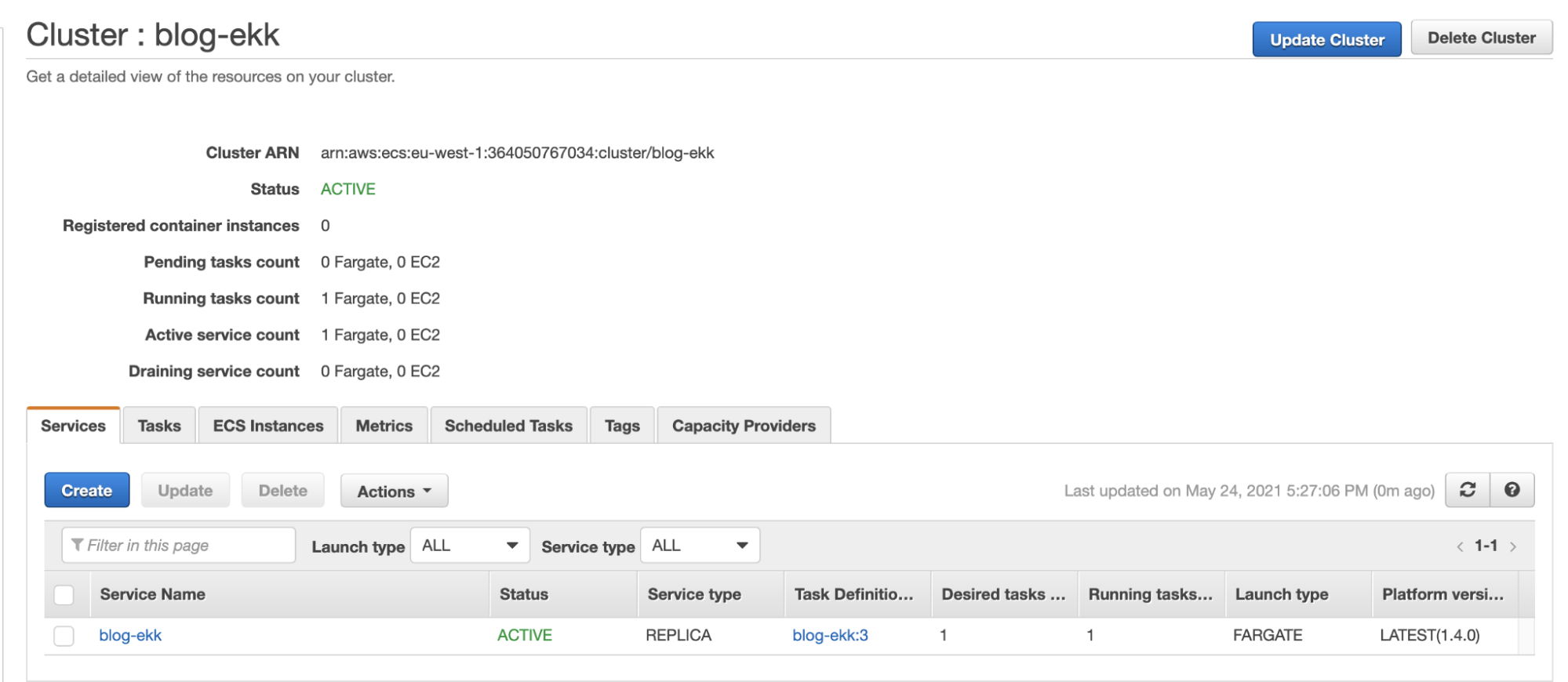
Ecco il nostro cluster Fargate con il service creato per la demo, blog-ekk:
Particolare attenzione è da porre nel definizione del task definiton, andremo infatti a utilizzare FireLens per l’integrazione nativa tra Fargate e Firehose:
FireLens è un log driver per i container ospitati su Amazon ECS che estende le sue funzionalità per la gestione dei log. Si appoggia a Fleuntd e Fluent Bit.
Di seguito viene riportata una semplificazione del task definition utilizzato da noi:
{ "family": "firelens-example-firehose", "taskRoleArn": "arn:aws:iam::XXXXXXXXXXXX:role/ecs_task_iam_role", "executionRoleArn": "arn:aws:iam::XXXXXXXXXXXX:role/ecs_task_execution_role", "containerDefinitions": [ { "essential": true, "image": "amazon/aws-for-fluent-bit:latest", "name": "log_router", "firelensConfiguration": { "type": "fluentbit" }, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "firelens-container", "awslogs-region": "eu-west-1", "awslogs-create-group": "true", "awslogs-stream-prefix": "firelens" } }, "memoryReservation": 50 }, { "essential": true, "image": "your-image-uri", "name": "app", "logConfiguration": { "logDriver":"awsfirelens", "options": { "Name": "firehose", "region": "eu-west-1"", "delivery_stream": "blog-ekk" } }, "memoryReservation": 100 } ] }
Se utilizziamo l’interfaccia grafica per la creazione del nostro task definition, una volta configurato il nostro container, modificando il log router in firelens apparirà in automatico il side container che si appoggia a FluentBit (container image: amazon / aws-for-fluent -bit: latest)
Non dimenticatevi di cambiare il task definition role affinché abbia i permessi di scrivere su Firehose!
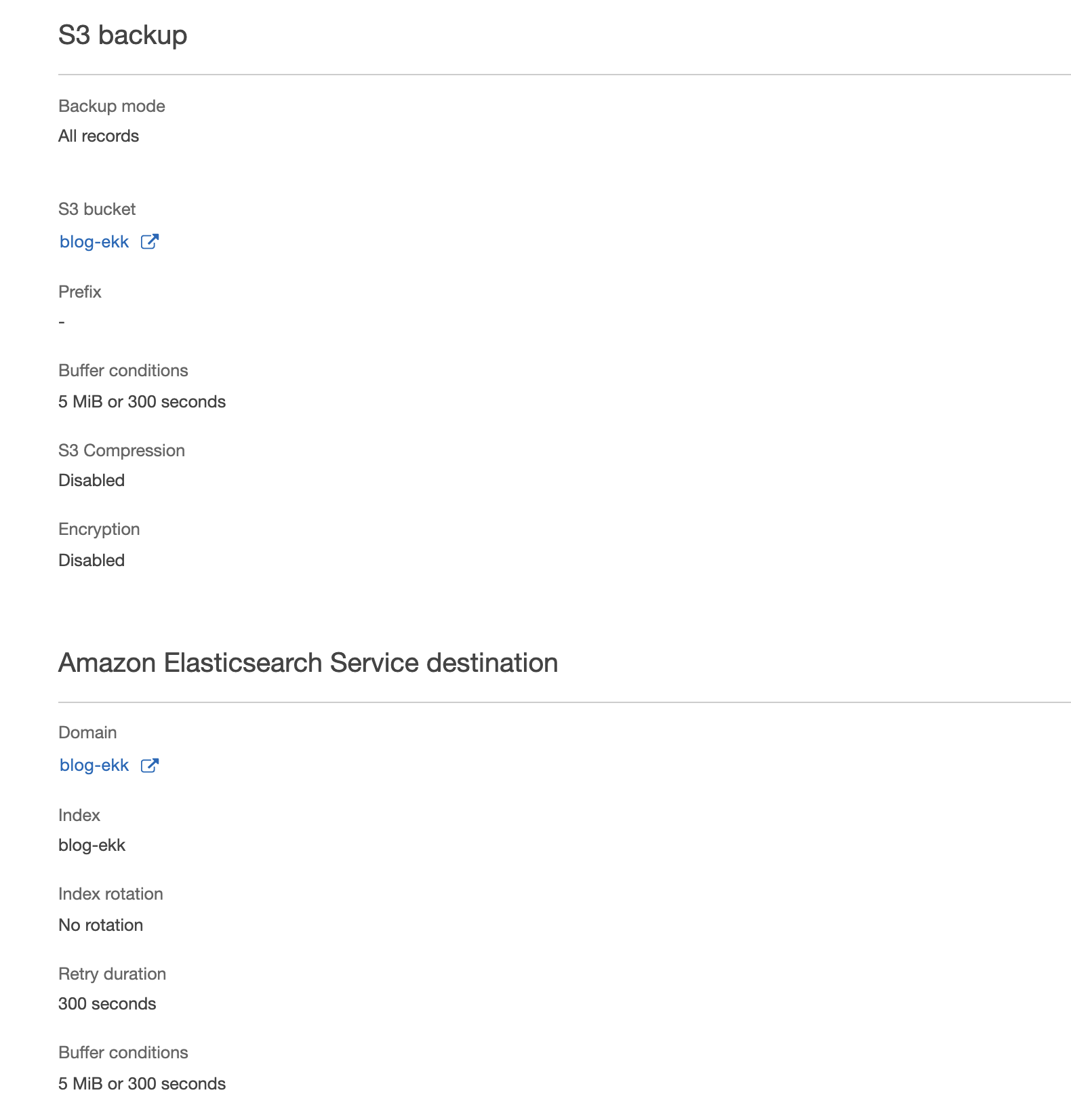
Perfetto, il sistema sender è stato configurato! Passiamo ora alla definizione del sistema di ingestion: Kinesis Firehose!
La sua configurazione risulta relativamente semplice. Nel nostro caso abbiamo utilizzato S3 come backup, Elasticsearch come destinazione e nessuna trasformazione Lambda.
Avete configurato tutto? Assicuratevi che il vostro Service su ECS sia up e running, nella sezione log potete controllare che il side container stia effettivamente inoltrato i log a Kinesis.
Per ulteriore verifica, potete controllare dalle metriche su Kinesis la corretta ricezione e il corretto inoltro sul server Elasticsearch.
Non ci resta che entrare sul dominio di Elasticsearch, nella pagina di overview troveremo l’indirizzo per accedere a Kibana. Nel nostro caso l’accesso verrà autenticato tramite username e password salvati e gestiti da Cognito:
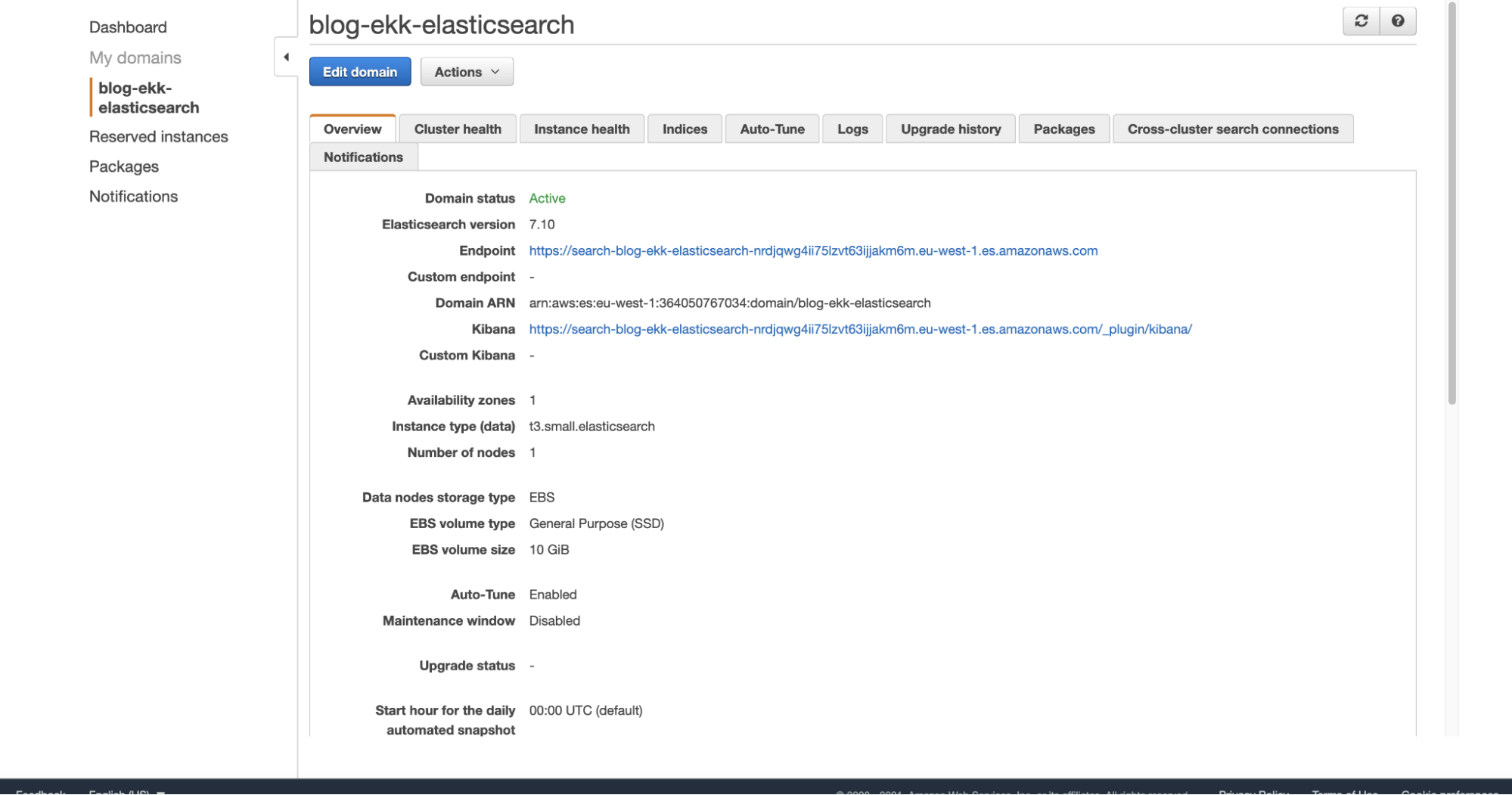
Ed ecco qui la nostra dashboard su Kibana:
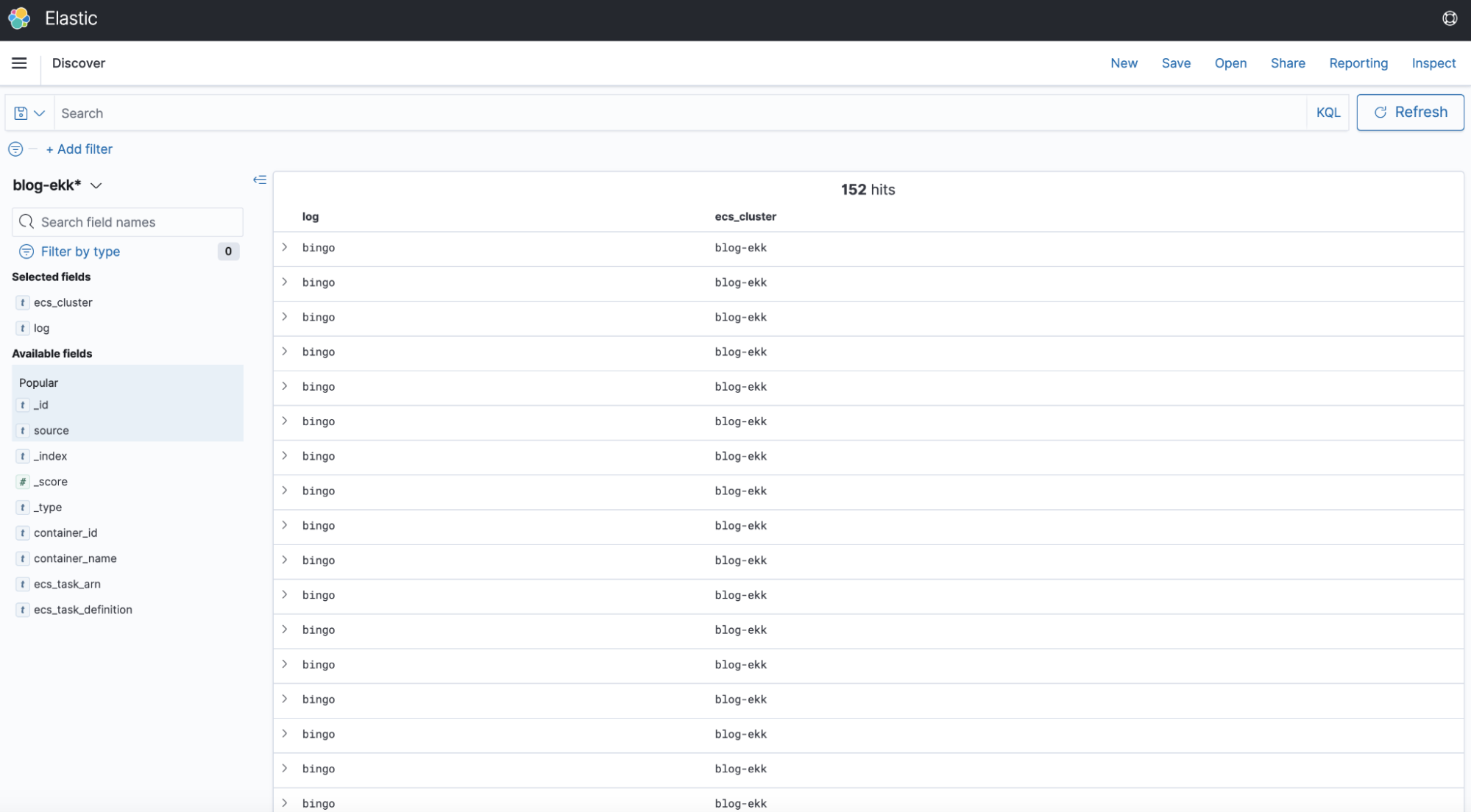
Il comportamento è quello atteso, abbiamo infatti creato un semplice container che scrive “bingo” periodicamente tramite un setInterval in Javascript.
Per concludere, in questo articolo abbiamo descritto i vantaggi dello stack EKK, una versione cloud-native AWS del classico stack ELK.
Abbiamo poi visto quali possibili servizi possiamo utilizzare per inoltrare i nostri log, approfondendo il caso di container ospitati su ECS in modalità Fargate.
Volete approfondire questa modalità con una guida passo-passo? O magari siete curiosi della soluzione partendo da macchine EC2? Scriveteci o commentate con le vostre considerazioni!
A tra 14 giorni con un nuovo articolo su #Proud2beCloud!


