
Telemetria Enterprise su AWS: Gestire backfill di dati massivi con ECS e Databricks senza far esp...
17 Giugno 2026 - 2 min. read
Keidi Xhafa


Tutti i professionisti IT hanno un debole per le infrastrutture stabili in cui tutto funziona senza intoppi, soprattutto durante il turno per il supporto 24/7.
Purtroppo però, nella maggior parte dei casi non è semplice nemmeno riuscire a capire se l’infrastruttura funziona correttamente oppure no, se è implementata a regola d’arte o se sta per esplodere tutto.
Questa situazione è strettamente legata al concetto di observability, definito come
la capacità di monitorare, misurare e comprendere lo stato di un sistema o di un'applicazione esaminandone l'output, i log e le metriche.
Quando un'organizzazione cresce in dimensioni e complessità, la capacità di estrarre informazioni sullo stato di salute dell'infrastruttura diventa fondamentale. In queste situazioni le metriche sono il miglior strumento per determinare lo stato di salute di un'infrastruttura.
Le metriche sono una rappresentazione numerica dei dati misurati nel tempo; sono utili per identificare tendenze, previsioni e anomalie. Affinché portino valore, le metriche devono essere centralizzate, elaborate, aggregate e presentate in modo significativo.
All’interno di AWS, i termini monitoring e observability dovrebbero immediatamente far pensare ad Amazon CloudWatch. Tutti conoscono Cloudwatch, giusto? I log groups, le metrics e gli events, tutto qui, corretto?
E se vi dicessi che CloudWatch è molto di più?
Ecco dunque 3+1 funzionalità di Amazon CloudWatch che non tutti conoscono.
Questa è probabilmente la mia feature preferita: con Synthetics è possibile creare dei “canaries”, ovvero degli script che vengono eseguiti in modo programmato per monitorare un sito web, un’API o un endpoint in generale. Con un canary è possibile simulare le azioni di un utente reale, rendendo davvero semplice scoprire se una pagina web non risponde o se un'API restituisce errori.
Esistono 3 metodi per creare un canary:
L'opzione più interessante è l’utilizzo dei blueprint in quanto mostrano il potenziale di questo strumento. L'interfaccia è chiara, i parametri impostabili dall’utente sono ben definiti, facili da compilare e le modifiche aggiornano in tempo reale lo script.
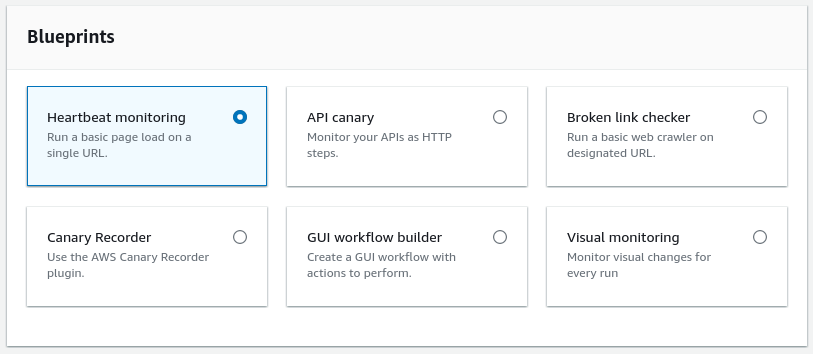
Come mostrato nell'immagine, questi sono i casi d’uso previsti nei blueprint:
Gli script possono essere scritti sia in Node.js utilizzando Puppeteer che in Python con Selenium, anche se alcuni blueprint sono privi dell’implementazione in Python. I runtime supportati consistono quindi in varie combinazioni di questi linguaggi, librerie e versioni di Chromium.
Se vi piace analizzare le metriche, è molto probabile che vi piaccia anche la matematica. Se non fosse questo il caso, non preoccupatevi, in questo paragrafo non verrà utilizzata alcuna funzione differenziale... forse.
Nelle occasioni in cui vi sia la necessità di una logica più complessa rispetto al semplice controllo dell’utilizzo della CPU, Cloudwatch viene in aiuto con la possibilità di utilizzare metriche derivate dalla combinazione di altre metriche.
Supponiamo che uno sviluppatore abbia appena corretto un bug che si presenta all’avvio di una funzione Lambda e, dopo la correzione, voglia verificare che la funzione non presenti ancora problemi nei primi millisecondi di esecuzione. Per fare ciò, il programmatore potrebbe verificare la presenza di errori mentre monitora il tempo di esecuzione medio della funzione.
L'immagine fornita mostra un'implementazione pratica di questo processo.
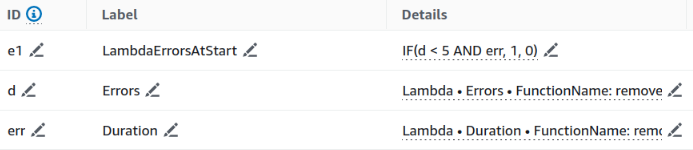
Naturalmente questo è un esempio molto semplice, ma attraverso l'uso di condizioni e delle funzioni presenti nel "math menu" è possibile creare espressioni più complesse. Il menù in questione offre moltissime funzioni, a partire dagli operatori matematici più comuni fino a condizioni, conversioni, ordinamento, filtri e ad altre query più specifiche.
Le metriche appena create possono poi essere aggiunte ad una dashboard (spoiler) o utilizzate per la creazione di allarmi.
Si può considerare monitoring se non ci sono delle dashboard? Non credo. Fortunatamente Cloudwatch mette a disposizione un servizio per la loro creazione. Le dashboard di Cloudwatch rendono molto semplice il monitoraggio di un intero workload, anche se composto da servizi diversi in regioni diverse e su account diversi, tutto in un’unica pagina.
Ad esempio, ecco una semplice dashboard che mostra il numero di chiamate a una particolare funzione Lambda e il suo tasso di fallimento.
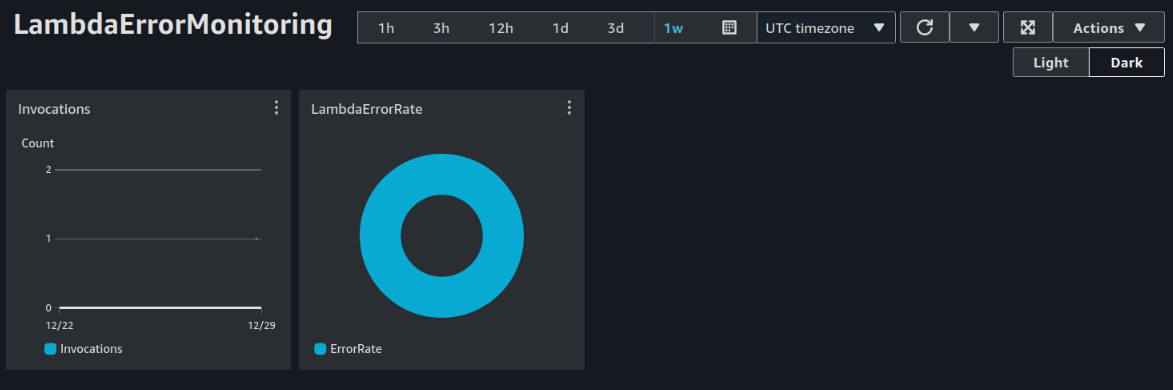
“E se la dashboard dovesse essere vista da persone che non hanno un account AWS?” Nessun problema. È possibile condividerla a un elenco di indirizzi e-mail selezionati o specificando un Identity Provider (IdP) di terze parti. Il proprietario di uno degli indirizzi e-mail consentiti dovrà creare la propria password che poi potrà utilizzare per visualizzare la dashboard.
Inoltre, vale la pena menzionare le "Dashboard automatiche". Si tratta di dashboard preconfigurate, incentrate su specifici servizi e già popolate di informazioni. Queste dashboard si rivelano molto utili in quanto consentono un rapido monitoraggio delle risorse senza la necessità di crearne di personalizzate.
Il nome di questa funzione potrebbe ricordare il celebre comando Unix presente nelle GNU coreutils… ed è giusto così! Live Tail replica la funzionalità di “tail -follow”, che legge continuamente le ultime righe di un file, ma su CloudWatch.
Con Live Tail è possibile seguire tutti i log di un log group selezionato senza dover continuamente premere il pulsante di aggiornamento nella pagina dei log events. Non è tutto, dopo aver selezionato il log group, la selezione del log stream è opzionale. Quest'ultima parte potrebbe non sembrare di grande importanza, ma chiunque abbia mai sviluppato un Lambda conosce la fatica di dover cambiare continuamente i log group per visualizzare i log più recenti. Questa funzionalità permette quindi di eliminare alcuni click ad ogni aggiornamento del codice della funzione, risparmiando molto tempo (ed energia mentale) durante lo sviluppo e, soprattutto, durante il debugging.
Per facilitare l'estrazione delle sole informazioni rilevanti dai logs è possibile utilizzare una regex, alcuni esempi:
Per chi non ama le regex (comprensible) esiste anche una sintassi più semplice:
In conclusione, il monitoring è spesso sottovalutato. Non ci si deve limitare a raccogliere i log "per sicurezza"; la comprensione del valore estratto dalle metriche grezze è la chiave per il miglioramento dell'infrastruttura. Naturalmente un approccio corretto al monitoraggio richiede uno sforzo, ma non si tratta di energia sprecata, bensì di un investimento. Capire come l'infrastruttura si comporta e reagisce ai cambiamenti è essenziale per mantenere una buona business continuity, aiuta a comprendere certi comportamenti e rende più facile operare in modo consapevole.
Siete a conoscenza di altre magie di Amazon CloudWatch? Non vediamo l'ora di ascoltarle!
Proud2beCloud è il blog di beSharp, APN Premier Consulting Partner italiano esperto nella progettazione, implementazione e gestione di infrastrutture Cloud complesse e servizi AWS avanzati. Prima di essere scrittori, siamo Solutions Architect che, dal 2007, lavorano quotidianamente con i servizi AWS. Siamo innovatori alla costante ricerca della soluzione più all'avanguardia per noi e per i nostri clienti. Su Proud2beCloud condividiamo regolarmente i nostri migliori spunti con chi come noi, per lavoro o per passione, lavora con il Cloud di AWS. Partecipa alla discussione!

